สิ่งที่ได้รับจากการฝึกประสบการณ์วิชาชีพ
ผมว่าสิ่งแรกที่ได้จากการเรียนวิชานี้ คือความตรงต่อเวลา
คนส่วนใหญ่ชอบมาสายกันเพราะต่างคนคิดว่าอีกฝ่ายต้อง
มาช้าและไม่อยากจะรอ
ในการเรียนวิชานี้ได้มีการจัดกิจกรรมหลายอย่าง
ที่เกี่ยวกับแขนงของตนที่เรียนอยู่ ซึ่งประโยชน์มากๆ
ที่สำคัญเป็นความรู้ที่เกี่ยวกับชีวิตในวัยทำงานของเราในอนาคต
ประสบการณ์ที่ได้ส่วนใหญ่เป็นวิทายากรถ่ายทอดให้เราซึ่ง
แต่ละอย่างนั้น มันจะต้องเกิดกับตัวเราแน่นอน ทำให้เรา
สามารถรับมือกับมันได้ในระดับหนึ่ง
พูดถึงบุคลิกภาพ วิชานี้สอนให้เราจักบุคลิกภาพที่แท้จริง
กล่าวคือ บุคลิกภาพเป็นสำคัญเพราะผู้คนที่พบเห็นเราสิ่งแรก
ที่เขาพบคือบุคลิกภายนอก การมีบุคลิกที่ดีทำให้เราได้เปรียบ
หลาย ๆ อย่าง เช่น ความเชื่อถือ ไว้เนื้อเชื่อใจ
ในวันที่มีการนิมนต์พระอาจารย์สมพงษ์ ซึ่งเป็นหนึ่งในคณะ ธรรมะเดลิเวอร์รี่ท่านได้ให้ข้อคิดหลายอย่าง
1.ทำวันนี้ให้ดีที่สุด วันหน้าจะได้ดี
2.น้ำที่ไหนก็สู้น้ำใจไม่ได้
3.เจออุปสรรคอย่าใช้อารมณ์ใช้หัวให้เยอะๆ
4.อย่า ท้อเมื่อพลาดพลั้ง
ทำ ความหวังขึ้นมาใหม่
นม นานสักเพียงใด
หก ล้มไปเพียงชั่วคราว
ข้อคิดเหล่านี้เป็นสิ่งที่ใช้ในการดำรงชีวิตประจำวัน เป็นสิ่งที่ทุกคนควรปฏิบัติตาม
สุดท้ายนี้ ขอบคุณอาจารย์ทุกท่านที่ทำให้ผู้เรียนวิชานี้ เป็นบัณฑิต
ที่พร้อมออกไปสู่โลกภายนอก โลกแห่งการแข่งขัน
ขอบคุณครับ
วันพุธที่ 14 ตุลาคม พ.ศ. 2552
วันพุธที่ 23 กันยายน พ.ศ. 2552
DTS09 15/09/2552
การเรียงลำดับ (sorting) เป็นการจัดให้เป็นระเบียบ
มีแบบแผน ช่วยให้การค้นหาสิ่งของหรือข้อมูล ซึ่งจะสามารถ
กระทำได้รวดเร็วและมีประสิทธิภาพ เช่น การค้นหา
ความหมายของคำในพจนานุกรม ทำได้ค่อนข้างง่ายและ
รวดเร็วเนื่องจากมีการเรียงลำดับคำตามตัวอักษรไว้อย่างมี
ระบบและเป็นระเบียบ หรือ การค้นหาหมายเลขโทรศัพท์ใน
สมุดโทรศัพท์ ซึ่งมีการเรียงลำดับ ตามชื่อและชื่อสกุลของ
เจ้าของโทรศัพท์ไว้ ทำให้สามารถค้นหา หมายเลข
โทรศัพท์ของคนที่ต้องการได้อย่างรวดเร็ว
การเรียงลำดับอย่างมีประสิทธิภาพ
หลักเกณฑ์ในการพิจารณาเพื่อเลือกวิธีการเรียงลำดับที่
ดี และเหมาะสมกับระบบงาน เพื่อให้ประสิทธิภาพในการ
ทำงานสูงสุด ควรจะต้องคำนึงถึงสิ่งต่าง ๆ ดังต่อไปนี้
(1) เวลาและแรงงานที่ต้องใช้ในการเขียนโปรแกรม
(2) เวลาที่เครื่องคอมพิวเตอร์ต้องใช้ในการทำงานตาม
โปรแกรมที่เขียน
(3) จำนวนเนื้อที่ในหน่วยความจำหลักมีเพียงพอ
หรือไม่
วิธีการเรียงลำดับ
เนื่องจากมีวิธีการมากมายที่สามารถใช้ในการเรียงลำดับ
ข้อมูลได้ บางวิธีก็มีขั้นตอนการจัดเรียงเป็นแบบง่าย ๆ ตรงไป
ตรงมา แต่ใช้เวลาในการจัดเรียงลำดับนาน และบางวิธีก็มี
ขั้นตอนในการจัดเรียงลำดับแบบซับซ้อนยุ่งยากแต่ใช้เวลา
ในการจัดเรียงไม่นานนัก ดังนั้นจึงควรศึกษาวิธีการจัดเรียง
ลำดับด้วยวิธีการต่าง ๆ เพื่อเลือกใช้วิธีการที่ดีและเหมาะสม
กับระบบงานนั้นที่สุด วิธีการเรียงลำดับสามารถแบ่งออกเป็น
2 ประเภท คือ
(1)การเรียงลำดับแบบภายใน (internal sorting)
เป็นการเรียงลำดับที่ข้อมูลทั้งหมดต้องอยู่ใน
หน่วยความจำหลัก เวลาที่ใช้ในการเรียงลำดับจะ
คำนึงถึงเวลาที่ใช้ในการเปรียบเทียบและเลื่อน
ข้อมูลภายในความจำหลัก
(2) การเรียงลำดับแบบภายนอก
(external sorting) เป็นการเรียงลำดับข้อมูลที่
เก็บอยู่ในหน่วยความจำสำรอง ซึ่งเป็นการ
เรียงลำดับข้อมูลในแฟ้มข้อมูล (file) เวลาที่ใช้ใน
การเรียงลำดับต้องคำนึงถึงเวลาที่เสียไประหว่าง
การถ่ายเทข้อมูลจากหน่วยความจำหลักและ
หน่วยความจำสำรองนอกเหนือจากเวลาที่ใช้
ในการเรียงลำดับข้อมูลแบบภายใน
การเรียงลำดับแบบเลือก (selection sort)
ทำการเลือกข้อมูลมาเก็บในตำแหน่งที่ ข้อมูลนั้นควรจะอยู่ทีละ
ตัว โดยทำการค้นหาข้อมูลนั้นในแต่ละรอบแบบเรียงลำดับ
ถ้าเป็นการเรียงลำดับจากน้อยไปมาก
1. ในรอบแรกจะทำการค้นหาข้อมูลตัวที่มีค่าน้อยที่สุดมาเก็บ
ไว้ที่ตำแหน่งที่ 1
2. ในรอบที่สองนำข้อมูลตัวที่มีค่าน้อยรองลงมาไปเก็บไว้ที่
ตำแหน่งที่สอง
3. ทำเช่นนี้ไปเรื่อย ๆ จนกระทั่งครบทุกค่า
ในที่สุดจะได้ข้อมูลเรียงลำดับจากน้อยไปมากตามที่ต้องการ

ในรอบที่ 1 ทำการเปรียบเทียบข้อมูลเพื่อค้นหาข้อมูลที่มีค่า
น้อยที่สุด คือ 22
นำไปวางที่ตำแหน่งที่ 1 สลับตำแหน่งกับ 35
ในรอบที่ 2 ทำการเปรียบเทียบอีกเพื่อค้นหาค่าที่น้อยที่สุด
รองลงมาโดยเริ่มค้นตั้งแต่ตำแหน่งที่ 2 เป็นต้นไปได้ค่าน้อย
ที่สุดคือ 35
นำไปวางที่ตำแหน่งที่ 2 สลับตำแหน่งกับ 67
ในรอบต่อไปก็ทำในทำนองเดียวกันจนกระทั่งถึงรอบ
สุดท้ายคือรอบที่ 7 จะได้ข้อมูลที่เรียงลำดับจากน้อยไปมาก
ตามที่ต้องการ
การเรียงลำดับแบบฟอง (Bubble Sort)
เป็นวิธีการเรียงลำดับที่มีการเปรียบเทียบข้อมูลใน
ตำแหน่งที่อยู่ติดกัน
1. ถ้าข้อมูลทั้งสองไม่อยู่ในลำดับที่ถูกต้องให้สลับตำแหน่ง
ที่อยู่กัน
2. ถ้าเป็นการเรียงลำดับจากน้อยไปมากให้นำข้อมูลตัวที่มี
ค่าน้อยกว่าอยู่ในตำแหน่งก่อนข้อมูลที่มีค่ามาก ถ้า
เป็นการเรียงลำดับจากมากไปน้อยให้นำข้อมูล ตัวที่มี
ค่ามากกว่าอยู่ในตำแหน่งก่อนข้อมูลที่มีค่าน้อย


จากตัวอย่าง การเปรียบเทียบจะเริ่มเปรียบเทียบ
จากคู่หลัง ในรอบที่ 1 เปรียบเทียบข้อมูลที่
ตำแหน่งที่ 7 กับ 8 ได้ว่า 43 น้อยกว่า 82 ให้
ทำการสลับตำแหน่งกันเพื่อให้ค่าที่น้อยกว่าอยู่ก่อน
ต่อไปเปรียบเทียบข้อมูลตำแหน่งที่ 6 กับ 7 ได้ว่า
43 น้อยกว่า 99 ให้ทำการสลับตำแหน่งกันอีก ทำ
การเปรียบเทียบเช่นนี้ในคู่ต่อไปเรื่อย ๆ จนกระทั่ง
ได้ค่าต่ำสุดอยู่ในตำแหน่งที่ 1
ในรอบที่ 2 ทำการเปรียบเทียบข้อมูลจากคู่หลังมา
คู่หน้าเช่นกัน แต่จะเปรียบเทียบถึงตำแหน่งที่ 2
เท่านั้นจนกระทั่งได้ค่าต่ำสุดรองลงมาไว้ในตำแหน่ง
ที่ 2 ในรอบต่อไปก็ทำในทำนองเดียวกันจนกระทั่ง
ถึงรอบสุดท้ายคือรอบที่ 7 จะเหลือข้อมูลที่ต้อง
เปรียบเทียบคู่เดียวคือข้อมูลในตำแหน่งที่ 7 กับ 8
เมื่อการจัดเรียงเสร็จเรียบร้อยเราจะได้ข้อมูลที่มีการ
เรียงลำดับจากน้อยไปมากตามที่ต้องการ
การเรียงลำดับแบบเร็ว เป็นวิธีการเรียงลำดับที่ใช้เวลาน้อยเหมาะ
สำหรับข้อมูลที่มีจำนวนมากที่ต้องการความรวดเร็ว
ในการทำงาน วิธีนี้จะเลือกข้อมูลจากกลุ่มข้อมูล
ขึ้นมาหนึ่งค่าเป็นค่าหลัก แล้วหาตำแหน่งที่ถูกต้อง
ให้กับค่าหลักนี้ เมื่อได้ตำแหน่งที่ถูกต้องแล้ว ใช้
ค่าหลักนี้เป็นหลักในการแบ่งข้อมูลออกเป็นสองส่วน
ถ้าเป็นการเรียงลำดับจากน้อยไปมาก ส่วนแรกอยู่
ในตอนหน้าข้อมูล ทั้งหมดจะมีค่าน้อยกว่าค่าหลักที่
เป็นตัวแบ่งส่วนอีกส่วนหนึ่งจะอยู่ในตำแหน่งตอนหลังข้อมูล
ทั้งหมด จะมีค่ามากกว่าค่าหลัก แล้วนำแต่ละ
ส่วนย่อยไปแบ่งย่อยในลักษณะเดียวกันต่อไป
จนกระทั่งแต่ละส่วนไม่สามารถแบ่งย่อยได้อีก
ต่อไปจะได้ข้อมูลที่มีการเรียงลำดับตามที่
ต้องการ

จากการเปรียบเทียบข้างต้นในที่สุดก็ได้
ตำแหน่งที่วางค่าหลัก 44 ซึ่งข้อมูลจะถูก
แบ่งเป็น 2 ส่วน ส่วนที่ 1 ข้อมูลทั้งหมดมีค่า
น้อยกว่าค่าหลัก และส่วนที่ 2 ข้อมูลทั้งหมดมี
ค่ามากกว่าค่าหลัก นำแต่ละส่วนไป
ดำเนินการเปรียบเทียบในลักษณะเดียวกัน
จนกระทั่งข้อมูลทั้งหมดเรียงลำดับจากน้อยไป
มากตามต้องการ
การเรียงลำดับแบบแทรก (insertion sort)
เป็นวิธีการเรียงลำดับที่ทำการเพิ่มสมาชิกใหม่เข้าไปใน
เซต ที่มีสมาชิกทุกตัวเรียงลำดับอยู่แล้ว และทำให้เซตใหม่
ที่ได้นี้มีสมาชิกทุกตัวเรียงลำดับด้วย วิธีการเรียงลำดับจะ
1. เริ่มต้นเปรียบเทียบจากข้อมูลในตำแหน่งที่ 1 กับ 2
หรือข้อมูลในตำแหน่งสุดท้ายและรองสุดท้ายก็ได้
ถ้าเป็นการเรียงลำดับจากน้อยไปมาก
2. จะต้องจัดให้ข้อมูลที่มีค่าน้อยอยู่ในตำแหน่งก่อน
ข้อมูลที่มีค่ามาก และถ้าเรียงจากมากไปน้อยจะก็จะ
จัดให้ข้อมูลที่มีค่ามากอยู่ในตำแหน่งก่อน
เช่น ต้องการเรียงลำดับข้อมูลจากน้อยไปมาก และ
เริ่มต้นนำข้อมูล 2 ตัวแรกมาเปรียบเทียบ ให้ข้อมูลที่มีค่า
น้อยกว่าอยู่ในตำแหน่งแรก จะได้ข้อมูลในเซตที่เรียงลำดับ
แล้วมีสมาชิก 2 ตัว จากนั้นนำสมาชิกใหม่เข้ามาโดยเริ่ม
เปรียบเทียบกับสมาชิกในเซตทีละตัว จะเริ่มเปรียบเทียบ
ตั้งแต่ตัวแรกหรือตัวหลังสุดก็ได้ ถ้าเปรียบเทียบตั้งแต่ตัว
แรกจะต้องหาตำแหน่งสมาชิกที่มีค่ามากกว่าสมาชิกใหม่
แล้วทำการถอยทุกค่าไปหนึ่งตำแหน่งตั้งแต่ตำแหน่งนั้นเป็น
ต้นไป เพื่อให้เกิดตำแหน่งว่างสำหรับแทรกสมาชิกใหม่ลง
ไปก็จะได้เซตที่เรียงลำดับใหม่
ข้อมูลเริ่มต้น

ถ้ามีจำนวนข้อมูลเป็น n การจัดเรียงแบบแทรกจะมี
การจัดเรียงทั้งหมดเท่ากับ n − 1 รอบ จำนวนครั้ง
ของการเปรียบเทียบในแต่ละรอบแตกต่างกันขึ้นอยู่กับ
ลักษณะการจัดเรียงของข้อมูลนั้น
กรณีที่ดีที่สุด คือ กรณีข้อมูลทั้งหมดจัดเรียงใน
ตำแหน่งที่ต้องการเรียบร้อยแล้ว กรณีนี้ในแต่ละรอบ
มีการเปรียบเทียบเพียงครั้งเดียว เพราะฉะนั้นจำนวน
ครั้งของการเปรียบเทียบเป็นดังนี้
จำนวนครั้งของการเปรียบเทียบ = n − 1 ครั้ง
กรณีที่แย่ที่สุด คือ กรณีที่ข้อมูลมีการเรียงลำดับในตำแหน่ง
ที่กลับกัน เช่น ต้องการเรียงลำดับจากน้อยไปมาก แต่
ข้อมูลมีค่าเรียงลำดับจากมากไปน้อย จำนวนครั้งของการ
เปรียบเทียบในแต่ละรอบดังนี้
ในรอบที่ 1 จำนวนครั้งของการเปรียบเทียบเป็น 1 ครั้ง
ในรอบที่ 2 จำนวนครั้งของการเปรียบเทียบเป็น 2 ครั้ง
จำนวนครั้งของการเปรียบเทียบ
= 1 + 2 + 3 + . . . +(n −2) + (n −1)
= n (n −1) / 2
มีแบบแผน ช่วยให้การค้นหาสิ่งของหรือข้อมูล ซึ่งจะสามารถ
กระทำได้รวดเร็วและมีประสิทธิภาพ เช่น การค้นหา
ความหมายของคำในพจนานุกรม ทำได้ค่อนข้างง่ายและ
รวดเร็วเนื่องจากมีการเรียงลำดับคำตามตัวอักษรไว้อย่างมี
ระบบและเป็นระเบียบ หรือ การค้นหาหมายเลขโทรศัพท์ใน
สมุดโทรศัพท์ ซึ่งมีการเรียงลำดับ ตามชื่อและชื่อสกุลของ
เจ้าของโทรศัพท์ไว้ ทำให้สามารถค้นหา หมายเลข
โทรศัพท์ของคนที่ต้องการได้อย่างรวดเร็ว
การเรียงลำดับอย่างมีประสิทธิภาพ
หลักเกณฑ์ในการพิจารณาเพื่อเลือกวิธีการเรียงลำดับที่
ดี และเหมาะสมกับระบบงาน เพื่อให้ประสิทธิภาพในการ
ทำงานสูงสุด ควรจะต้องคำนึงถึงสิ่งต่าง ๆ ดังต่อไปนี้
(1) เวลาและแรงงานที่ต้องใช้ในการเขียนโปรแกรม
(2) เวลาที่เครื่องคอมพิวเตอร์ต้องใช้ในการทำงานตาม
โปรแกรมที่เขียน
(3) จำนวนเนื้อที่ในหน่วยความจำหลักมีเพียงพอ
หรือไม่
วิธีการเรียงลำดับ
เนื่องจากมีวิธีการมากมายที่สามารถใช้ในการเรียงลำดับ
ข้อมูลได้ บางวิธีก็มีขั้นตอนการจัดเรียงเป็นแบบง่าย ๆ ตรงไป
ตรงมา แต่ใช้เวลาในการจัดเรียงลำดับนาน และบางวิธีก็มี
ขั้นตอนในการจัดเรียงลำดับแบบซับซ้อนยุ่งยากแต่ใช้เวลา
ในการจัดเรียงไม่นานนัก ดังนั้นจึงควรศึกษาวิธีการจัดเรียง
ลำดับด้วยวิธีการต่าง ๆ เพื่อเลือกใช้วิธีการที่ดีและเหมาะสม
กับระบบงานนั้นที่สุด วิธีการเรียงลำดับสามารถแบ่งออกเป็น
2 ประเภท คือ
(1)การเรียงลำดับแบบภายใน (internal sorting)
เป็นการเรียงลำดับที่ข้อมูลทั้งหมดต้องอยู่ใน
หน่วยความจำหลัก เวลาที่ใช้ในการเรียงลำดับจะ
คำนึงถึงเวลาที่ใช้ในการเปรียบเทียบและเลื่อน
ข้อมูลภายในความจำหลัก
(2) การเรียงลำดับแบบภายนอก
(external sorting) เป็นการเรียงลำดับข้อมูลที่
เก็บอยู่ในหน่วยความจำสำรอง ซึ่งเป็นการ
เรียงลำดับข้อมูลในแฟ้มข้อมูล (file) เวลาที่ใช้ใน
การเรียงลำดับต้องคำนึงถึงเวลาที่เสียไประหว่าง
การถ่ายเทข้อมูลจากหน่วยความจำหลักและ
หน่วยความจำสำรองนอกเหนือจากเวลาที่ใช้
ในการเรียงลำดับข้อมูลแบบภายใน
การเรียงลำดับแบบเลือก (selection sort)
ทำการเลือกข้อมูลมาเก็บในตำแหน่งที่ ข้อมูลนั้นควรจะอยู่ทีละ
ตัว โดยทำการค้นหาข้อมูลนั้นในแต่ละรอบแบบเรียงลำดับ
ถ้าเป็นการเรียงลำดับจากน้อยไปมาก
1. ในรอบแรกจะทำการค้นหาข้อมูลตัวที่มีค่าน้อยที่สุดมาเก็บ
ไว้ที่ตำแหน่งที่ 1
2. ในรอบที่สองนำข้อมูลตัวที่มีค่าน้อยรองลงมาไปเก็บไว้ที่
ตำแหน่งที่สอง
3. ทำเช่นนี้ไปเรื่อย ๆ จนกระทั่งครบทุกค่า
ในที่สุดจะได้ข้อมูลเรียงลำดับจากน้อยไปมากตามที่ต้องการ
ในรอบที่ 1 ทำการเปรียบเทียบข้อมูลเพื่อค้นหาข้อมูลที่มีค่า
น้อยที่สุด คือ 22
นำไปวางที่ตำแหน่งที่ 1 สลับตำแหน่งกับ 35
ในรอบที่ 2 ทำการเปรียบเทียบอีกเพื่อค้นหาค่าที่น้อยที่สุด
รองลงมาโดยเริ่มค้นตั้งแต่ตำแหน่งที่ 2 เป็นต้นไปได้ค่าน้อย
ที่สุดคือ 35
นำไปวางที่ตำแหน่งที่ 2 สลับตำแหน่งกับ 67
ในรอบต่อไปก็ทำในทำนองเดียวกันจนกระทั่งถึงรอบ
สุดท้ายคือรอบที่ 7 จะได้ข้อมูลที่เรียงลำดับจากน้อยไปมาก
ตามที่ต้องการ
การเรียงลำดับแบบฟอง (Bubble Sort)
เป็นวิธีการเรียงลำดับที่มีการเปรียบเทียบข้อมูลใน
ตำแหน่งที่อยู่ติดกัน
1. ถ้าข้อมูลทั้งสองไม่อยู่ในลำดับที่ถูกต้องให้สลับตำแหน่ง
ที่อยู่กัน
2. ถ้าเป็นการเรียงลำดับจากน้อยไปมากให้นำข้อมูลตัวที่มี
ค่าน้อยกว่าอยู่ในตำแหน่งก่อนข้อมูลที่มีค่ามาก ถ้า
เป็นการเรียงลำดับจากมากไปน้อยให้นำข้อมูล ตัวที่มี
ค่ามากกว่าอยู่ในตำแหน่งก่อนข้อมูลที่มีค่าน้อย
จากตัวอย่าง การเปรียบเทียบจะเริ่มเปรียบเทียบ
จากคู่หลัง ในรอบที่ 1 เปรียบเทียบข้อมูลที่
ตำแหน่งที่ 7 กับ 8 ได้ว่า 43 น้อยกว่า 82 ให้
ทำการสลับตำแหน่งกันเพื่อให้ค่าที่น้อยกว่าอยู่ก่อน
ต่อไปเปรียบเทียบข้อมูลตำแหน่งที่ 6 กับ 7 ได้ว่า
43 น้อยกว่า 99 ให้ทำการสลับตำแหน่งกันอีก ทำ
การเปรียบเทียบเช่นนี้ในคู่ต่อไปเรื่อย ๆ จนกระทั่ง
ได้ค่าต่ำสุดอยู่ในตำแหน่งที่ 1
ในรอบที่ 2 ทำการเปรียบเทียบข้อมูลจากคู่หลังมา
คู่หน้าเช่นกัน แต่จะเปรียบเทียบถึงตำแหน่งที่ 2
เท่านั้นจนกระทั่งได้ค่าต่ำสุดรองลงมาไว้ในตำแหน่ง
ที่ 2 ในรอบต่อไปก็ทำในทำนองเดียวกันจนกระทั่ง
ถึงรอบสุดท้ายคือรอบที่ 7 จะเหลือข้อมูลที่ต้อง
เปรียบเทียบคู่เดียวคือข้อมูลในตำแหน่งที่ 7 กับ 8
เมื่อการจัดเรียงเสร็จเรียบร้อยเราจะได้ข้อมูลที่มีการ
เรียงลำดับจากน้อยไปมากตามที่ต้องการ
การเรียงลำดับแบบเร็ว เป็นวิธีการเรียงลำดับที่ใช้เวลาน้อยเหมาะ
สำหรับข้อมูลที่มีจำนวนมากที่ต้องการความรวดเร็ว
ในการทำงาน วิธีนี้จะเลือกข้อมูลจากกลุ่มข้อมูล
ขึ้นมาหนึ่งค่าเป็นค่าหลัก แล้วหาตำแหน่งที่ถูกต้อง
ให้กับค่าหลักนี้ เมื่อได้ตำแหน่งที่ถูกต้องแล้ว ใช้
ค่าหลักนี้เป็นหลักในการแบ่งข้อมูลออกเป็นสองส่วน
ถ้าเป็นการเรียงลำดับจากน้อยไปมาก ส่วนแรกอยู่
ในตอนหน้าข้อมูล ทั้งหมดจะมีค่าน้อยกว่าค่าหลักที่
เป็นตัวแบ่งส่วนอีกส่วนหนึ่งจะอยู่ในตำแหน่งตอนหลังข้อมูล
ทั้งหมด จะมีค่ามากกว่าค่าหลัก แล้วนำแต่ละ
ส่วนย่อยไปแบ่งย่อยในลักษณะเดียวกันต่อไป
จนกระทั่งแต่ละส่วนไม่สามารถแบ่งย่อยได้อีก
ต่อไปจะได้ข้อมูลที่มีการเรียงลำดับตามที่
ต้องการ
จากการเปรียบเทียบข้างต้นในที่สุดก็ได้
ตำแหน่งที่วางค่าหลัก 44 ซึ่งข้อมูลจะถูก
แบ่งเป็น 2 ส่วน ส่วนที่ 1 ข้อมูลทั้งหมดมีค่า
น้อยกว่าค่าหลัก และส่วนที่ 2 ข้อมูลทั้งหมดมี
ค่ามากกว่าค่าหลัก นำแต่ละส่วนไป
ดำเนินการเปรียบเทียบในลักษณะเดียวกัน
จนกระทั่งข้อมูลทั้งหมดเรียงลำดับจากน้อยไป
มากตามต้องการ
การเรียงลำดับแบบแทรก (insertion sort)
เป็นวิธีการเรียงลำดับที่ทำการเพิ่มสมาชิกใหม่เข้าไปใน
เซต ที่มีสมาชิกทุกตัวเรียงลำดับอยู่แล้ว และทำให้เซตใหม่
ที่ได้นี้มีสมาชิกทุกตัวเรียงลำดับด้วย วิธีการเรียงลำดับจะ
1. เริ่มต้นเปรียบเทียบจากข้อมูลในตำแหน่งที่ 1 กับ 2
หรือข้อมูลในตำแหน่งสุดท้ายและรองสุดท้ายก็ได้
ถ้าเป็นการเรียงลำดับจากน้อยไปมาก
2. จะต้องจัดให้ข้อมูลที่มีค่าน้อยอยู่ในตำแหน่งก่อน
ข้อมูลที่มีค่ามาก และถ้าเรียงจากมากไปน้อยจะก็จะ
จัดให้ข้อมูลที่มีค่ามากอยู่ในตำแหน่งก่อน
เช่น ต้องการเรียงลำดับข้อมูลจากน้อยไปมาก และ
เริ่มต้นนำข้อมูล 2 ตัวแรกมาเปรียบเทียบ ให้ข้อมูลที่มีค่า
น้อยกว่าอยู่ในตำแหน่งแรก จะได้ข้อมูลในเซตที่เรียงลำดับ
แล้วมีสมาชิก 2 ตัว จากนั้นนำสมาชิกใหม่เข้ามาโดยเริ่ม
เปรียบเทียบกับสมาชิกในเซตทีละตัว จะเริ่มเปรียบเทียบ
ตั้งแต่ตัวแรกหรือตัวหลังสุดก็ได้ ถ้าเปรียบเทียบตั้งแต่ตัว
แรกจะต้องหาตำแหน่งสมาชิกที่มีค่ามากกว่าสมาชิกใหม่
แล้วทำการถอยทุกค่าไปหนึ่งตำแหน่งตั้งแต่ตำแหน่งนั้นเป็น
ต้นไป เพื่อให้เกิดตำแหน่งว่างสำหรับแทรกสมาชิกใหม่ลง
ไปก็จะได้เซตที่เรียงลำดับใหม่
ข้อมูลเริ่มต้น
ถ้ามีจำนวนข้อมูลเป็น n การจัดเรียงแบบแทรกจะมี
การจัดเรียงทั้งหมดเท่ากับ n − 1 รอบ จำนวนครั้ง
ของการเปรียบเทียบในแต่ละรอบแตกต่างกันขึ้นอยู่กับ
ลักษณะการจัดเรียงของข้อมูลนั้น
กรณีที่ดีที่สุด คือ กรณีข้อมูลทั้งหมดจัดเรียงใน
ตำแหน่งที่ต้องการเรียบร้อยแล้ว กรณีนี้ในแต่ละรอบ
มีการเปรียบเทียบเพียงครั้งเดียว เพราะฉะนั้นจำนวน
ครั้งของการเปรียบเทียบเป็นดังนี้
จำนวนครั้งของการเปรียบเทียบ = n − 1 ครั้ง
กรณีที่แย่ที่สุด คือ กรณีที่ข้อมูลมีการเรียงลำดับในตำแหน่ง
ที่กลับกัน เช่น ต้องการเรียงลำดับจากน้อยไปมาก แต่
ข้อมูลมีค่าเรียงลำดับจากมากไปน้อย จำนวนครั้งของการ
เปรียบเทียบในแต่ละรอบดังนี้
ในรอบที่ 1 จำนวนครั้งของการเปรียบเทียบเป็น 1 ครั้ง
ในรอบที่ 2 จำนวนครั้งของการเปรียบเทียบเป็น 2 ครั้ง
จำนวนครั้งของการเปรียบเทียบ
= 1 + 2 + 3 + . . . +(n −2) + (n −1)
= n (n −1) / 2
วันอังคารที่ 8 กันยายน พ.ศ. 2552
DTS08 08/09/2552
กราฟ (Graph) เป็นโครงสร้างข้อมูล
แบบไม่ใช่เชิงเส้น อีกชนิดหนึ่ง กราฟเป็น
โครงสร้างข้อมูลที่มีการนำไปใช้ในงาน
ที่เกี่ยวข้องกับการแก้ปัญหาที่ค่อนข้างซับซ้อน
เช่น การวางข่าย งานคอมพิวเตอร์ การ
วิเคราะห์เส้นทางวิกฤติ และปัญหาเส้นทาง
ที่สั้นที่สุด
นิยามของกราฟ
กราฟ เป็นโครงสร้างข้อมูลแบบไม่ใช่เชิงเส้น
ที่ประกอบ ด้วยกลุ่มของสิ่งสองสิ่งคือ
(1) โหนด (Nodes) หรือ เวอร์เทกซ์
(Vertexes)
(2) เส้นเชื่อมระหว่างโหนด เรียก เอ็จ (Edges)
กราฟที่มีเอ็จเชื่อมระหว่างโหนดสองโหนด
ถ้าเอ็จไม่มีลำดับ ความสัมพันธ์จะเรียกกราฟนั้นว่า
กราฟแบบไม่มีทิศทาง (Undirected Graphs)
และถ้ากราฟนั้นมีเอ็จที่มีลำดับ
ความสัมพันธ์หรือมีทิศทางกำกับด้วยเรียกกราฟ
นั้นว่า กราฟแบบมีทิศทาง
(Directed Graphs)
บางครั้งเรียกว่า ไดกราฟ (Digraph)
ถ้าต้องการอ้างถึงเอ็จแต่ละเส้นสามารถ
เขียนชื่อเอ็จกำกับไว้ก็ได้
การแทนกราฟในหน่วยความจำ
ในการปฏิบัติการกับโครงสร้างกราฟ สิ่งที่
ต้องการจัดเก็บ จากกราฟโดยทั่วไปก็คือ เอ็จ ซึ่ง
เป็นเส้นเชื่อมระหว่างโหนดสองโหนด มีวิธีการ
จัดเก็บหลายวิธี วิธีที่ง่ายและตรงไปตรงมา
ที่สุดคือ การเก็บเอ็จในแถวลำดับ 2 มิติ N1 N2

การแทนกราฟด้วยแถวลำดับ2มิติ กรณีกราฟไม่มีทิศทาง
การแทนกราฟในหน่วยความจำด้วยวิธีเก็บ
เอ็จทั้งหมดใน แถวลำดับ 2 มิติ จะค่อนข้าง
เปลืองเนื้อที่ เนื่องจากมีบางเอ็จที่เก็บซ้ำ
อาจหลีกเลี่ยงปัญหานี้ได้โดยใช้แถวลำดับ 2 มิติ
เก็บโหนดและ พอยเตอร์ชี้ไปยงตำแหน่งของ
โหนดต่าง ๆ ที่สัมพันธ์ด้วย และใช้ แถวลำดับ
1 มิติเก็บโหนดต่าง ๆ ที่มีความสัมพันธ์กับโหนด
ในแถวลำดับ 2 มิติ N2

กราฟในแถวลำดับ 2 มิติเก็บโหมดเเละพอยเตอร์ของกราฟ
การจัดเก็บกราฟด้วยวิธีเก็บโหนดและพอยน์เตอร์
นี้ยุ่งยาก ในการจัดการเพิ่มขึ้นเนื่องจากต้องเก็บโหนด
และพอยน์เตอร์ในแถวลำดับ 2 มิติ และต้องจัดเก็บ
โหนดที่สัมพันธ์ด้วยในแถวลำดับ
1 มิติ อย่างไรก็ตามทั้งสองวิธีไม่เหมาะกับกราฟที่มีการ
เปลี่ยนแปลง ตลอดเวลา ควรใช้ในกราฟที่ไม่มีการ
เปลี่ยนแปลงตลอดการใช้งาน
เพราะถ้ามีการเปลี่ยนแปลงส่วนใดส่วนหนึ่งของกราฟจะ
กระทบกับส่วนอื่น ๆ ที่อยู่ในระดับที่ต่ำกว่าด้วยเสมอ
กราฟที่มีการเปลี่ยนแปลงตลอดเวลา
อาจจะใช้วิธีแอดจาเซนซีลิสต์
(Adjacency List) ซึ่งเป็นวิธีที่คล้ายวิธี
จัดเก็บกราฟด้วยการเก็บโหนดและพอยน์
เตอร์ แต่ต่างกันตรงที่ จะใช้ ลิงค์ลิสต์แทน
เพื่อความสะดวกในการเปลี่ยนแปลงแก้ไข

การแทนกราฟด้วยวิธีแอดจาเซนซีลิสต์
การท่องไปในกราฟ
การท่องไปในกราฟ (graph traversal) คือ
กระบวนการเข้าไปเยือนโหนดในกราฟ โดยมีหลักในการ
ทำงานคือ แต่ละโหนดจะถูกเยือนเพียงครั้งเดียว สำหรับ
การท่องไปในทรีเพื่อเยือนแต่ละโหนดนั้นจะมีเส้นทางเดียว
แต่ในกราฟระหว่างโหนดอาจจะมีหลายเส้นทาง ดังนั้น
เพื่อป้องกันการท่องไปในเส้นทางที่ซ้ำเดิมจึงจำเป็นต้องทำ
เครื่องหมายบริเวณที่ได้เยือนเสร็จเรียบร้อยแล้ว
เพื่อไม่ให้เข้าไปเยือนอีก สำหรับเทคนิคการท่องไปในกราฟมี2วิธีดังนี้
1. การท่องแบบกว้าง (Breadth First Traversal)
วิธีนี้ทำโดยเลือกโหนดที่เป็นจุดเริ่มต้น ต่อมาให้เยือนโหนด
อื่นที่ใกล้กันกับโหนดเริ่มต้นทีละระดับจนกระทั่งเยือนหมดทุกโหนดในกราฟ
2. การท่องแบบลึก (Depth First Traversal)
การทำงานคล้ายกับการท่องทีละระดับของทรี โดย
กำหนดเริ่มต้นที่โหนดแรกและเยือนโหนดถัดไปตาม
แนววิถีนั้นจนกระทั่งนำไปสู่ปลายวิถีนั้น จากนั้น
ย้อนกลับ (backtrack) ตามแนววิถีเดิมนั้น จนกระทั่ง
สามารถดำเนินการต่อเนื่องเข้าสู่แนววิถีอื่น ๆ เพื่อเยือน
โหนดอื่น ๆ ต่อไปจนครบทุกโหนด
แบบไม่ใช่เชิงเส้น อีกชนิดหนึ่ง กราฟเป็น
โครงสร้างข้อมูลที่มีการนำไปใช้ในงาน
ที่เกี่ยวข้องกับการแก้ปัญหาที่ค่อนข้างซับซ้อน
เช่น การวางข่าย งานคอมพิวเตอร์ การ
วิเคราะห์เส้นทางวิกฤติ และปัญหาเส้นทาง
ที่สั้นที่สุด
นิยามของกราฟ
กราฟ เป็นโครงสร้างข้อมูลแบบไม่ใช่เชิงเส้น
ที่ประกอบ ด้วยกลุ่มของสิ่งสองสิ่งคือ
(1) โหนด (Nodes) หรือ เวอร์เทกซ์
(Vertexes)
(2) เส้นเชื่อมระหว่างโหนด เรียก เอ็จ (Edges)
กราฟที่มีเอ็จเชื่อมระหว่างโหนดสองโหนด
ถ้าเอ็จไม่มีลำดับ ความสัมพันธ์จะเรียกกราฟนั้นว่า
กราฟแบบไม่มีทิศทาง (Undirected Graphs)
และถ้ากราฟนั้นมีเอ็จที่มีลำดับ
ความสัมพันธ์หรือมีทิศทางกำกับด้วยเรียกกราฟ
นั้นว่า กราฟแบบมีทิศทาง
(Directed Graphs)
บางครั้งเรียกว่า ไดกราฟ (Digraph)
ถ้าต้องการอ้างถึงเอ็จแต่ละเส้นสามารถ
เขียนชื่อเอ็จกำกับไว้ก็ได้
การแทนกราฟในหน่วยความจำ
ในการปฏิบัติการกับโครงสร้างกราฟ สิ่งที่
ต้องการจัดเก็บ จากกราฟโดยทั่วไปก็คือ เอ็จ ซึ่ง
เป็นเส้นเชื่อมระหว่างโหนดสองโหนด มีวิธีการ
จัดเก็บหลายวิธี วิธีที่ง่ายและตรงไปตรงมา
ที่สุดคือ การเก็บเอ็จในแถวลำดับ 2 มิติ N1 N2
การแทนกราฟด้วยแถวลำดับ2มิติ กรณีกราฟไม่มีทิศทาง
การแทนกราฟในหน่วยความจำด้วยวิธีเก็บ
เอ็จทั้งหมดใน แถวลำดับ 2 มิติ จะค่อนข้าง
เปลืองเนื้อที่ เนื่องจากมีบางเอ็จที่เก็บซ้ำ
อาจหลีกเลี่ยงปัญหานี้ได้โดยใช้แถวลำดับ 2 มิติ
เก็บโหนดและ พอยเตอร์ชี้ไปยงตำแหน่งของ
โหนดต่าง ๆ ที่สัมพันธ์ด้วย และใช้ แถวลำดับ
1 มิติเก็บโหนดต่าง ๆ ที่มีความสัมพันธ์กับโหนด
ในแถวลำดับ 2 มิติ N2
กราฟในแถวลำดับ 2 มิติเก็บโหมดเเละพอยเตอร์ของกราฟ
การจัดเก็บกราฟด้วยวิธีเก็บโหนดและพอยน์เตอร์
นี้ยุ่งยาก ในการจัดการเพิ่มขึ้นเนื่องจากต้องเก็บโหนด
และพอยน์เตอร์ในแถวลำดับ 2 มิติ และต้องจัดเก็บ
โหนดที่สัมพันธ์ด้วยในแถวลำดับ
1 มิติ อย่างไรก็ตามทั้งสองวิธีไม่เหมาะกับกราฟที่มีการ
เปลี่ยนแปลง ตลอดเวลา ควรใช้ในกราฟที่ไม่มีการ
เปลี่ยนแปลงตลอดการใช้งาน
เพราะถ้ามีการเปลี่ยนแปลงส่วนใดส่วนหนึ่งของกราฟจะ
กระทบกับส่วนอื่น ๆ ที่อยู่ในระดับที่ต่ำกว่าด้วยเสมอ
กราฟที่มีการเปลี่ยนแปลงตลอดเวลา
อาจจะใช้วิธีแอดจาเซนซีลิสต์
(Adjacency List) ซึ่งเป็นวิธีที่คล้ายวิธี
จัดเก็บกราฟด้วยการเก็บโหนดและพอยน์
เตอร์ แต่ต่างกันตรงที่ จะใช้ ลิงค์ลิสต์แทน
เพื่อความสะดวกในการเปลี่ยนแปลงแก้ไข
การแทนกราฟด้วยวิธีแอดจาเซนซีลิสต์
การท่องไปในกราฟ
การท่องไปในกราฟ (graph traversal) คือ
กระบวนการเข้าไปเยือนโหนดในกราฟ โดยมีหลักในการ
ทำงานคือ แต่ละโหนดจะถูกเยือนเพียงครั้งเดียว สำหรับ
การท่องไปในทรีเพื่อเยือนแต่ละโหนดนั้นจะมีเส้นทางเดียว
แต่ในกราฟระหว่างโหนดอาจจะมีหลายเส้นทาง ดังนั้น
เพื่อป้องกันการท่องไปในเส้นทางที่ซ้ำเดิมจึงจำเป็นต้องทำ
เครื่องหมายบริเวณที่ได้เยือนเสร็จเรียบร้อยแล้ว
เพื่อไม่ให้เข้าไปเยือนอีก สำหรับเทคนิคการท่องไปในกราฟมี2วิธีดังนี้
1. การท่องแบบกว้าง (Breadth First Traversal)
วิธีนี้ทำโดยเลือกโหนดที่เป็นจุดเริ่มต้น ต่อมาให้เยือนโหนด
อื่นที่ใกล้กันกับโหนดเริ่มต้นทีละระดับจนกระทั่งเยือนหมดทุกโหนดในกราฟ
2. การท่องแบบลึก (Depth First Traversal)
การทำงานคล้ายกับการท่องทีละระดับของทรี โดย
กำหนดเริ่มต้นที่โหนดแรกและเยือนโหนดถัดไปตาม
แนววิถีนั้นจนกระทั่งนำไปสู่ปลายวิถีนั้น จากนั้น
ย้อนกลับ (backtrack) ตามแนววิถีเดิมนั้น จนกระทั่ง
สามารถดำเนินการต่อเนื่องเข้าสู่แนววิถีอื่น ๆ เพื่อเยือน
โหนดอื่น ๆ ต่อไปจนครบทุกโหนด
วันอังคารที่ 25 สิงหาคม พ.ศ. 2552
DTS07 25/08/2552
ทรี (Tree) เป็นโครงสร้างข้อมูลที่ความสัมพันธ์
ระหว่าง โหนดจะมีความสัมพันธ์ลดหลั่นกันเป็นลำดับ
ชั้น (Hierarchical Relationship)
ได้มีการนำรูปแบบทรีไปประยุกต์ใช้ในงาน
ต่าง ๆ อย่างแพร่หลาย ส่วนมากจะใช้สำหรับแสดง
ความสัมพันธ์ระหว่างข้อมูล
แต่ละโหนดจะมีความสัมพันธ์กับโหนดใน
ระดับที่ต่ำลงมา หนึ่งระดับได้หลาย ๆ โหนด
เรียกโหนดดังกล่าวว่า โหนดแม่ (Parent or
Mother Node)
โหนดที่อยู่ต่ำกว่าโหนดแม่อยู่หนึ่งระดับ
เรียกว่า โหนดลูก (Child or Son Node)
โหนดที่อยู่ในระดับสูงสุดและไม่มีโหนดแม่
เรียกว่า โหนดราก (Root Node)
โหนดที่มีโหนดแม่เป็นโหนดเดียวกัน
เรียกว่า โหนดพี่น้อง (Siblings)
โหนดที่ไม่มีโหนดลูก เรียกว่า
โหนดใบ (Leave Node)
เส้นเชื่อมแสดงความสัมพันธ์ระหว่าง
โหนดสองโหนด
การแปลงทรีทั่วไปให้เป็นไบนารีทรี
ขั้นตอนการแปลงทรีทั่วๆ ไปให้เป็น
ไบนารีทรี มีลำดับขั้นตอนการแปลง ดังต่อไปนี้
1. ให้โหนดแม่ชี้ไปยังโหนดลูกคนโต แล้วลบ
ความสัมพันธ์ ระหว่างโหนดแม่และโหนดลูกอื่น ๆ
2. ให้เชื่อมความสัมพันธ์ระหว่างโหนดพี่น้อง
3. จับให้ทรีย่อยทางขวาเอียงลงมา 45 องศา

การท่องไปในไบนารีทรี
ปฏิบัติการที่สำคัญในไบนารีทรี คือ การท่องไปใน
ไบนารีทรี (Traversing Binary Tree) เพื่อเข้าไปเยือนทุก ๆ
โหนดในทรี ซึ่งวิธีการท่องเข้าไปต้องเป็นไปอย่างมีระบบแบบ
แผน สามารถเยือนโหนดทุก ๆ โหนด ๆ ละหนึ่งครั้ง
วิธีการท่องไปนั้นมีด้วยกันหลายแบบแล้วแต่ว่าต้องการลำดับ
ขั้นตอนการเยือนอย่างไร โหนดที่ถูกเยือน
อาจเป็นโหนดแม่ (แทนด้วย N)
ทรีย่อยทางซ้าย (แทนด้วย L)
หรือทรีย่อยทางขวา (แทนด้วย R
วิธีการท่องเข้าไปในทรี 6 วิธี คือ NLR
LNR LRN NRL RNL และ RLN แต่
วิธีการท่องเข้าไปไบนารีทรีที่นิยมใช้
กันมากเป็นการท่องจากซ้ายไปขวา 3 แบบแรก
เท่านั้นคือ NLR LNR และ LRN ซึ่งลักษณะ
การนิยามเป็นนิยามแบบ รีเคอร์ซีฟ
(Recursive) ซึ่งขั้นตอนการท่องไปในแต่ละแบบมีดังนี้
1. การท่องไปแบบพรีออร์เดอร์
(Preorder Traversal)
เป็นการเดินเข้าไปเยือนโหนดต่าง ๆ ในทรีด้วยวิธี
NLR มีขั้นตอนการเดินดังต่อไปนี้
(1) เยือนโหนดราก
(2) ท่องไปในทรีย่อยทางซ้ายแบบพรีออร์เดอร์
(3) ท่องไปในทรีย่อยทางขวาแบบพรีออร์เดอร์
NLR
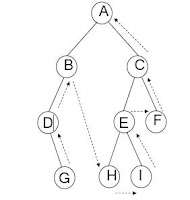
เส้นทางการท่องในทรีแบบพรีออร์เดอร์ จะได้ ABDGCEHIF
2.การท่องไปแบบอินออร์เดอร์
(Inorder Traversal)
เป็นการเดินเข้าไปเยือนโหนดต่าง ๆ
ในทรีด้วยวิธี LNR
มีขั้นตอนการเดินดังต่อไปนี้
(1) ท่องไปในทรีย่อยทางซ้ายแบบอินออร์เดอร์
(2) เยือนโหนดราก
(3) ท่องไปในทรีย่อยทางขวาแบบอินออร์เดอร์
LNR

เส้นทางการท่องในทรีแบบอินออร์เดอร์ จะได้ DGBAHEICF
การท่องไปแบบโพสออร์เดอร์
(Postorder Traversal)
เป็นการเดินเข้าไปเยือนโหนดต่าง ๆ
ในทรีด้วยวิธี LRN มีขั้นตอนการเดินดังต่อไปนี้
(1) ท่องไปในทรีย่อยทางซ้ายแบบโพสต์ออร์เดอร์
(2) ท่องไปในทรีย่อยทางขวาแบบโพสต์ออร์เดอร์
(3) เยือนโหนดราก
LRN

เส้นทางการท่องในทรีแบบโพสต์ออร์เดอร์ จะได้ GDBHIEFCA
เอ็กซ์เพรสชันทรี (Expression Tree)
เป็นการนำเอาโครงสร้างทรีไปใช้เก็บนิพจน์
ทางคณิตศาสตร์โดยเป็นไบนารีทรี ซึ่งแต่ละโหนด
เก็บตัวดำเนินการ (Operator) และและตัวถูกดำเนินการ
(Operand) ของนิพจน์คณิตศาสตร์นั้น ๆ ไว้ หรือ
อาจจะเก็บค่านิพจน์ทางตรรกะ (Logical Expression)
นิพจน์เหล่านี้เมื่อแทนในทรีต้องคำนึงลำดับขั้นตอน
ในการคำนวณตามความสำคัญของเครื่องหมายด้วย
ไบนารีเซิร์ชทรี
ไบนารีเซิร์ชทรี (Binary Search Tree)
เป็นไบนารีทรีที่มีคุณสมบัติที่ว่าทุก ๆ โหนด
ในทรี ค่าของโหนดรากมีค่ามากกว่าค่าของทุก
โหนดในทรีย่อยทางซ้าย และมีค่าน้อยกว่า
หรือเท่ากับค่าของทุกโหนดในทรีย่อยทางขวา
และในแต่ละทรีย่อยก็มี คุณสมบัติเช่นเดียวกัน

ไบนารีเซิร์ชทรีของเลขจำนวน ไบนารีเซิร์ชทรีของสัตว์
ปฏิบัติการในไบนารีเซิร์ชทรี ปฏิบัติการ
เพิ่มโหนดเข้าหรือดึงโหนดออกจากไบนารีเซิร์ชทรี
ค่อนข้างยุ่งยากกว่าปฏิบัติการในโครงสร้างอื่น ๆ
เนื่องจากหลังปฏิบัติการเสร็จเรียบร้อยแล้วต้อง
คำนึงถึงความเป็นไบนารีเซิร์ชทรีของทรีนั้นด้วย
ระหว่าง โหนดจะมีความสัมพันธ์ลดหลั่นกันเป็นลำดับ
ชั้น (Hierarchical Relationship)
ได้มีการนำรูปแบบทรีไปประยุกต์ใช้ในงาน
ต่าง ๆ อย่างแพร่หลาย ส่วนมากจะใช้สำหรับแสดง
ความสัมพันธ์ระหว่างข้อมูล
แต่ละโหนดจะมีความสัมพันธ์กับโหนดใน
ระดับที่ต่ำลงมา หนึ่งระดับได้หลาย ๆ โหนด
เรียกโหนดดังกล่าวว่า โหนดแม่ (Parent or
Mother Node)
โหนดที่อยู่ต่ำกว่าโหนดแม่อยู่หนึ่งระดับ
เรียกว่า โหนดลูก (Child or Son Node)
โหนดที่อยู่ในระดับสูงสุดและไม่มีโหนดแม่
เรียกว่า โหนดราก (Root Node)
โหนดที่มีโหนดแม่เป็นโหนดเดียวกัน
เรียกว่า โหนดพี่น้อง (Siblings)
โหนดที่ไม่มีโหนดลูก เรียกว่า
โหนดใบ (Leave Node)
เส้นเชื่อมแสดงความสัมพันธ์ระหว่าง
โหนดสองโหนด
การแปลงทรีทั่วไปให้เป็นไบนารีทรี
ขั้นตอนการแปลงทรีทั่วๆ ไปให้เป็น
ไบนารีทรี มีลำดับขั้นตอนการแปลง ดังต่อไปนี้
1. ให้โหนดแม่ชี้ไปยังโหนดลูกคนโต แล้วลบ
ความสัมพันธ์ ระหว่างโหนดแม่และโหนดลูกอื่น ๆ
2. ให้เชื่อมความสัมพันธ์ระหว่างโหนดพี่น้อง
3. จับให้ทรีย่อยทางขวาเอียงลงมา 45 องศา
การท่องไปในไบนารีทรี
ปฏิบัติการที่สำคัญในไบนารีทรี คือ การท่องไปใน
ไบนารีทรี (Traversing Binary Tree) เพื่อเข้าไปเยือนทุก ๆ
โหนดในทรี ซึ่งวิธีการท่องเข้าไปต้องเป็นไปอย่างมีระบบแบบ
แผน สามารถเยือนโหนดทุก ๆ โหนด ๆ ละหนึ่งครั้ง
วิธีการท่องไปนั้นมีด้วยกันหลายแบบแล้วแต่ว่าต้องการลำดับ
ขั้นตอนการเยือนอย่างไร โหนดที่ถูกเยือน
อาจเป็นโหนดแม่ (แทนด้วย N)
ทรีย่อยทางซ้าย (แทนด้วย L)
หรือทรีย่อยทางขวา (แทนด้วย R
วิธีการท่องเข้าไปในทรี 6 วิธี คือ NLR
LNR LRN NRL RNL และ RLN แต่
วิธีการท่องเข้าไปไบนารีทรีที่นิยมใช้
กันมากเป็นการท่องจากซ้ายไปขวา 3 แบบแรก
เท่านั้นคือ NLR LNR และ LRN ซึ่งลักษณะ
การนิยามเป็นนิยามแบบ รีเคอร์ซีฟ
(Recursive) ซึ่งขั้นตอนการท่องไปในแต่ละแบบมีดังนี้
1. การท่องไปแบบพรีออร์เดอร์
(Preorder Traversal)
เป็นการเดินเข้าไปเยือนโหนดต่าง ๆ ในทรีด้วยวิธี
NLR มีขั้นตอนการเดินดังต่อไปนี้
(1) เยือนโหนดราก
(2) ท่องไปในทรีย่อยทางซ้ายแบบพรีออร์เดอร์
(3) ท่องไปในทรีย่อยทางขวาแบบพรีออร์เดอร์
NLR
เส้นทางการท่องในทรีแบบพรีออร์เดอร์ จะได้ ABDGCEHIF
2.การท่องไปแบบอินออร์เดอร์
(Inorder Traversal)
เป็นการเดินเข้าไปเยือนโหนดต่าง ๆ
ในทรีด้วยวิธี LNR
มีขั้นตอนการเดินดังต่อไปนี้
(1) ท่องไปในทรีย่อยทางซ้ายแบบอินออร์เดอร์
(2) เยือนโหนดราก
(3) ท่องไปในทรีย่อยทางขวาแบบอินออร์เดอร์
LNR
เส้นทางการท่องในทรีแบบอินออร์เดอร์ จะได้ DGBAHEICF
การท่องไปแบบโพสออร์เดอร์
(Postorder Traversal)
เป็นการเดินเข้าไปเยือนโหนดต่าง ๆ
ในทรีด้วยวิธี LRN มีขั้นตอนการเดินดังต่อไปนี้
(1) ท่องไปในทรีย่อยทางซ้ายแบบโพสต์ออร์เดอร์
(2) ท่องไปในทรีย่อยทางขวาแบบโพสต์ออร์เดอร์
(3) เยือนโหนดราก
LRN
เส้นทางการท่องในทรีแบบโพสต์ออร์เดอร์ จะได้ GDBHIEFCA
เอ็กซ์เพรสชันทรี (Expression Tree)
เป็นการนำเอาโครงสร้างทรีไปใช้เก็บนิพจน์
ทางคณิตศาสตร์โดยเป็นไบนารีทรี ซึ่งแต่ละโหนด
เก็บตัวดำเนินการ (Operator) และและตัวถูกดำเนินการ
(Operand) ของนิพจน์คณิตศาสตร์นั้น ๆ ไว้ หรือ
อาจจะเก็บค่านิพจน์ทางตรรกะ (Logical Expression)
นิพจน์เหล่านี้เมื่อแทนในทรีต้องคำนึงลำดับขั้นตอน
ในการคำนวณตามความสำคัญของเครื่องหมายด้วย
ไบนารีเซิร์ชทรี
ไบนารีเซิร์ชทรี (Binary Search Tree)
เป็นไบนารีทรีที่มีคุณสมบัติที่ว่าทุก ๆ โหนด
ในทรี ค่าของโหนดรากมีค่ามากกว่าค่าของทุก
โหนดในทรีย่อยทางซ้าย และมีค่าน้อยกว่า
หรือเท่ากับค่าของทุกโหนดในทรีย่อยทางขวา
และในแต่ละทรีย่อยก็มี คุณสมบัติเช่นเดียวกัน
ไบนารีเซิร์ชทรีของเลขจำนวน ไบนารีเซิร์ชทรีของสัตว์
ปฏิบัติการในไบนารีเซิร์ชทรี ปฏิบัติการ
เพิ่มโหนดเข้าหรือดึงโหนดออกจากไบนารีเซิร์ชทรี
ค่อนข้างยุ่งยากกว่าปฏิบัติการในโครงสร้างอื่น ๆ
เนื่องจากหลังปฏิบัติการเสร็จเรียบร้อยแล้วต้อง
คำนึงถึงความเป็นไบนารีเซิร์ชทรีของทรีนั้นด้วย
วันจันทร์ที่ 10 สิงหาคม พ.ศ. 2552
iostream.h
#include<iostream.h>
#include<conio.h>
void main()
{
float rad;
const float PI = 3.14159;
clrscr();
cout<< "Please enter radius of circle : ";
cin>>rad;
float area = PI*rad*rad;
cout<< "\n\nRadius of circle = "<
}
#include<conio.h>
void main()
{
float rad;
const float PI = 3.14159;
clrscr();
cout<< "Please enter radius of circle : ";
cin>>rad;
float area = PI*rad*rad;
cout<< "\n\nRadius of circle = "<
}
วันพุธที่ 5 สิงหาคม พ.ศ. 2552
DTS06 4/08/2552
สแตก (Stack) เป็นโครงสร้างข้อมูลที่ ข้อมูลแบบลิเนียร์ลิสต์
ที่มีคุณสมบัติ ที่ว่า การเพิ่มหรือลบข้อมูลในสแตก จะกระทำที่
ปลายข้างเดียวกัน ซึ่งเรียกว่า Top ของสแตก (TopOf Stack)
และ ลักษณะที่สำคัญของสแตกคือ ข้อมูลที่ใส่หลังสุดจะถูกนำออกมา
จากสแตกเป็นลำดับแรกสุด เรียกคุณสมบัตินี้ว่าLIFO (Last In First Out)
การดำเนินงานพื้นฐานของสแตกการทำงานต่าง ๆ ของสแตกจะ กระทำที่ปลายข้างหนึ่งของ
สแตกเท่านั้น ดังนั้นจะต้องมีตัวชี้ตำแหน่ง ข้อมูลบนสุดของสแตกด้วยการทำงานของสแตกจะ
ประกอบด้วยกระบวนการ 3 กระบวนการที่สำคัญ คือ
1.Push คือ การนำข้อมูลใส่ลงไปในสแตกเช่น
สแตก s ต้องการใส่ข้อมูล i ในสแตก จะได้push (s,i) คือ ใส่ข้อมูล i
ลงไปที่ทอปของสแตก sในการเพิ่มข้อมูลลงในสแตก จะต้องทำการตรวจสอบว่าสแตก
เต็มหรือไม่ ถ้าไม่เต็มก็สามารถเพิ่มข้อมูลลงไปในสแตกได้ แล้วปรับตัวชี้ตำแหน่งให้
ไปชี้ที่ตำแหน่งข้อมูลใหม่ ถ้าสแตกเต็ม (Stack Overflow) ก็จะ
ไม่สามารถเพิ่ม ข้อมูลเข้าไปในสแตกได้อีก
2. Pop คือ การนำข้อมูลออกจากส่วนบนสุดของสแตกเช่น
ต้องการนำข้อมูลออกจากสแตก sไปไว้ที่ตัวแปร iจะได้ i = pop (s)การนำข้อมูลออกจากสแตก
ถ้าสแตกมีสมาชิกเพียง 1ตัว แล้วนำสมาชิกออกจากสแตก จะเกิดสภาวะสแตกว่าง
(Stack Empty) คือ ไม่มีสมาชิกอยู่ในสแตกเลยการแทนที่ข้อมูลของสแตกสามารถทำได้ 2 วิธี คือ
1. การแทนที่ข้อมูลของสแตกแบบลิงค์ลิสต์
2. การแทนที่ข้อมูลของสแตก
การแทนที่ข้อมูลของสแตกแบบลิงค์ลิสต์จะประกอบไปด้วย2 ส่วน คือ
1. Head Node จะประกอบไปด้วย 2 ส่วน
คือ top pointer และจำนวนสมาชิกในสแตก
2. Data Node จะประกอบไปด้วยข้อมูล (Data) และพอยเตอร์ ที่ชี้ไปยังข้อมูลตัวถัดไป


การประยุกต์ใช้สแตกการประยุกต์ใช้สแตก จะใช้ในงานด้านปฏิบัติการของ
เครื่องคอมพิวเตอร์ที่ขั้นตอนการทำงานต้องการเก็บข่าวสารอันดับแรกสุดไว้ใช้หลังสุด
เช่น การทำงานของโปรแกรมแปลภาษานำไปใช้ในเรื่องของการโปรแกรมที่เรียกใช้โปรแกรมย่อย
การคำนวณนิพจน์ทางคณิตศาสตร์ และรีเคอร์ชั่น (Recursionขั้นตอนการแปลงจากนิพจน์ Infix เป็นนิพจน์Postfix
1. อ่านอักขระในนิพจน์ Infix เข้ามาทีละตัว
2. ถ้าเป็นตัวถูกดำเนินการจะถูกย้ายไปเป็นตัวอักษรในนิพจน์ Postfix
3. ถ้าเป็นตัวดำเนินการ จะนำค่าลำดับความสำคัญของตัว ดำเนินการที่อ่านเข้ามาเทียบกับค่าลำดับความสำคัญของตัวดำเนินการ
ที่อยู่บนสุดของสแตก- ถ้ามีความสำคัญมากกว่า จะถูก push ลงในสแตก- ถ้ามีความสำคัญน้อยกว่าหรือเท่ากัน จะต้อง pop
ตัวดำเนินการที่อยู่ในสแตกขณะนั้นไปเรียงต่อกับตัวอักษรในนิพจน์ Postfix4. ตัวดำเนินการที่เป็นวงเล็บปิด “)”
จะไม่ push ลงในสแตกแต่มีผลให้ตัวดำเนินการอื่น ๆ ถูก pop ออกจากสแตกนำไป เรียงต่อกันในนิพจน์ Postfix จนกว่าจะเจอ
“(”popวงเล็บเปิดออกจากสแตกแต่ไม่นำไปเรียงต่อ5. เมื่อทำการอ่านตัวอักษรในนิพจน์ Infixหมดแล้ว
ให้ทำการ Pop ตัวดำเนินการทุกตัวในสแตกนำมาเรียงต่อในนิพจน์Postfix
ที่มีคุณสมบัติ ที่ว่า การเพิ่มหรือลบข้อมูลในสแตก จะกระทำที่
ปลายข้างเดียวกัน ซึ่งเรียกว่า Top ของสแตก (TopOf Stack)
และ ลักษณะที่สำคัญของสแตกคือ ข้อมูลที่ใส่หลังสุดจะถูกนำออกมา
จากสแตกเป็นลำดับแรกสุด เรียกคุณสมบัตินี้ว่าLIFO (Last In First Out)
การดำเนินงานพื้นฐานของสแตกการทำงานต่าง ๆ ของสแตกจะ กระทำที่ปลายข้างหนึ่งของ
สแตกเท่านั้น ดังนั้นจะต้องมีตัวชี้ตำแหน่ง ข้อมูลบนสุดของสแตกด้วยการทำงานของสแตกจะ
ประกอบด้วยกระบวนการ 3 กระบวนการที่สำคัญ คือ
1.Push คือ การนำข้อมูลใส่ลงไปในสแตกเช่น
สแตก s ต้องการใส่ข้อมูล i ในสแตก จะได้push (s,i) คือ ใส่ข้อมูล i
ลงไปที่ทอปของสแตก sในการเพิ่มข้อมูลลงในสแตก จะต้องทำการตรวจสอบว่าสแตก
เต็มหรือไม่ ถ้าไม่เต็มก็สามารถเพิ่มข้อมูลลงไปในสแตกได้ แล้วปรับตัวชี้ตำแหน่งให้
ไปชี้ที่ตำแหน่งข้อมูลใหม่ ถ้าสแตกเต็ม (Stack Overflow) ก็จะ
ไม่สามารถเพิ่ม ข้อมูลเข้าไปในสแตกได้อีก
2. Pop คือ การนำข้อมูลออกจากส่วนบนสุดของสแตกเช่น
ต้องการนำข้อมูลออกจากสแตก sไปไว้ที่ตัวแปร iจะได้ i = pop (s)การนำข้อมูลออกจากสแตก
ถ้าสแตกมีสมาชิกเพียง 1ตัว แล้วนำสมาชิกออกจากสแตก จะเกิดสภาวะสแตกว่าง
(Stack Empty) คือ ไม่มีสมาชิกอยู่ในสแตกเลยการแทนที่ข้อมูลของสแตกสามารถทำได้ 2 วิธี คือ
1. การแทนที่ข้อมูลของสแตกแบบลิงค์ลิสต์
2. การแทนที่ข้อมูลของสแตก
การแทนที่ข้อมูลของสแตกแบบลิงค์ลิสต์จะประกอบไปด้วย2 ส่วน คือ
1. Head Node จะประกอบไปด้วย 2 ส่วน
คือ top pointer และจำนวนสมาชิกในสแตก
2. Data Node จะประกอบไปด้วยข้อมูล (Data) และพอยเตอร์ ที่ชี้ไปยังข้อมูลตัวถัดไป
การประยุกต์ใช้สแตกการประยุกต์ใช้สแตก จะใช้ในงานด้านปฏิบัติการของ
เครื่องคอมพิวเตอร์ที่ขั้นตอนการทำงานต้องการเก็บข่าวสารอันดับแรกสุดไว้ใช้หลังสุด
เช่น การทำงานของโปรแกรมแปลภาษานำไปใช้ในเรื่องของการโปรแกรมที่เรียกใช้โปรแกรมย่อย
การคำนวณนิพจน์ทางคณิตศาสตร์ และรีเคอร์ชั่น (Recursionขั้นตอนการแปลงจากนิพจน์ Infix เป็นนิพจน์Postfix
1. อ่านอักขระในนิพจน์ Infix เข้ามาทีละตัว
2. ถ้าเป็นตัวถูกดำเนินการจะถูกย้ายไปเป็นตัวอักษรในนิพจน์ Postfix
3. ถ้าเป็นตัวดำเนินการ จะนำค่าลำดับความสำคัญของตัว ดำเนินการที่อ่านเข้ามาเทียบกับค่าลำดับความสำคัญของตัวดำเนินการ
ที่อยู่บนสุดของสแตก- ถ้ามีความสำคัญมากกว่า จะถูก push ลงในสแตก- ถ้ามีความสำคัญน้อยกว่าหรือเท่ากัน จะต้อง pop
ตัวดำเนินการที่อยู่ในสแตกขณะนั้นไปเรียงต่อกับตัวอักษรในนิพจน์ Postfix4. ตัวดำเนินการที่เป็นวงเล็บปิด “)”
จะไม่ push ลงในสแตกแต่มีผลให้ตัวดำเนินการอื่น ๆ ถูก pop ออกจากสแตกนำไป เรียงต่อกันในนิพจน์ Postfix จนกว่าจะเจอ
“(”popวงเล็บเปิดออกจากสแตกแต่ไม่นำไปเรียงต่อ5. เมื่อทำการอ่านตัวอักษรในนิพจน์ Infixหมดแล้ว
ให้ทำการ Pop ตัวดำเนินการทุกตัวในสแตกนำมาเรียงต่อในนิพจน์Postfix
วันอังคารที่ 28 กรกฎาคม พ.ศ. 2552
DTS05 28/07/2552
ลิงค์ลิสต์ (Linked List) เป็นวิธีการเก็บข้อมูลอย่างต่อเนื่องของอิลิเมนต์ต่าง ๆ โดยมีพอยเตอร์เป็นตัวเชื่อมต่อ
แต่ละอิลิเมนท์ เรียกว่าโนด (Node) ซึ่งในแต่ละโนดจะประกอบไปด้วย 2 ส่วน คือData จะเก็บข้อมูลของอิลิเมนท์ และ
ส่วนที่สอง คือ Link Field จะทำหน้าที่เก็บตำแหน่งของโนดต่อไปในลิสต์
โครงสร้างข้อมูลแบบลิงค์ลิสต์
โครงสร้างข้อมูลแบบลิงค์ลิสต์จะแบ่งเป็น 2 ส่วน คือ
1. Head Structure จะประกอบไปด้วย 3 ส่วน
ได้แก่ จำนวนโหนดในลิสต์ (Count) พอยเตอร์ที่ชี้ไปยังโหนดที่เข้าถึง (Pos) และพอยเตอร์ที่ชี้ไปยัง
โหนดข้อมูลแรกของลิสต์ (Head)
2. Data Node Structure จะประกอบไปด้วยข้อมูล(Data)
และพอยเตอร์ที่ชี้ไปยังข้อมูลตัวถัดไปกระบวนงานและฟังก์ชั่นที่ใช้ดำเนินงานพื้นฐาน
1. กระบวนงาน Create Listหน้าที่ สร้างสิสต์ว่างผลลัพธ์ ลิสต์ว่าง

2. กระบวนงาน Insert Nodeหน้าที่เพิ่มข้อมูลลงไปในลิสต์บริเวณตำแหน่งที่ต้องการข้อมูลนำเข้า ลิสต์ ข้อมูล
และตำแหน่งผลลัพธ์ ลิสต์ที่มีการเปลี่ยนแปลง
3. กระบวนงาน Delete Nodeหน้าที่ ลบสมาชิกในลิสต์บริเวณตำแหน่งที่ต้องการข้อมูลนำเข้า ข้อมูลและตำแหน่งผลลัพธ์ ลิสต์ที่มีการเปลี่ยนแปลง

4. กระบวนงาน Search listหน้าที่ ค้นหาข้อมูลในลิสต์ที่ต้องการข้อมูลนำเข้าลิสต์ผลลัพธ์ ค่าจริงถ้าพบข้อมูล ค่าเท็จถ้าไม่พบข้อมูล
5. กระบวนงาน Traverseหน้าที่ ท่องไปในลิสต์เพื่อเข้าถึงและประมวลผลข้อมูลนำเข้าลิสต์ผลลัพธ์ ขึ้นกับการประมวลผล เช่นเปลี่ยนแปลงค่าใน node , รวมฟิลด์ในลิสต์ ,คำนวณค่าเฉลี่ยของฟิลด์ เป็นต้น

Linked list traversal
6. กระบวนงาน Retrieve Nodeหน้าที่ หาตำแหน่งข้อมูลจากลิสต์ข้อมูลนำเข้าลิสต์ผลลัพธ์ ตำแหน่งข้อมูลที่อยู่ในลิสต์
7. ฟังก์ชั่น EmptyListหน้าที่ ทดสอบว่าลิสต์ว่างข้อมูลนำเข้า ลิสต์ผลลัพธ์ เป็นจริง ถ้าลิสต์ว่างเป็นเท็จ ถ้าลิสต์ไม่ว่าง
Algorithm emptyList (val pList )
Pre pList is a pointer to a valid list head structure
Return true if list empty, false if list contains data
1. Return (pList->count equal to zero)
End emptyList
10. กระบวนงาน destroy listหน้าที่ ทำลายลิสต์
ข้อมูลนำเข้า ลิสต์
ผลลัพธ์ ไม่มีลิสต์

วันอังคารที่ 14 กรกฎาคม พ.ศ. 2552
DTS04 14/07/2552
โครงสร้างข้อมูลแบบเซ็ต
เป็นโครงสร้างข้อมูลที่ข้อมูลแต่ละตัวไม่มีความสัมพันธ์กัน
ในภาษาซีจะไม่มีประเภทข้อมูลแบบเซ็ตนี้เหมือนกับในภาษาปาสคาล
แต่สามารถใช้หลักการของการดำเนินงานแบบเช็ตมาใช้ได้
วิธีการแก้ปัญหาเบื้องต้น
- จะต้องกำหนดเซ็ตของผู้เรียนที่ลงทะเบียนเรียนในแต่ละวิชา
- นำเซ็ตดังกล่าวที่ได้มาทำการ intersection กัน หากมีเซ็ตใดที่
ทำการ intersect กันแล้ว มีข้อมูลสมาชิกในเซ็ตที่ซ้ำกันอยู่
จะไม่สามารถจัดให้วิชาดังกล่าวอยู่ในวันเวลาเดียวกันได้ตัวอย่างดังกล่าว
เป็นการนำแนวความคิดเรื่องการจัดการแบบเช็ตมาประยุกใช้งานโครงสร้างข้อมูลแบบสตริงสตริง (String) หรือ สตริงของอักขระ (CharacterString) เป็นข้อมูลที่ประกอบไปด้วย
ตัวอักษร ตัวเลขหรือเครื่องหมายเรียงติดต่อกันไป
รวมทั้งช่องว่างการประยุกต์ใช้คอมพิวเตอร์ที่เกี่ยวกับข้อมูลที่เป็นสตริงมีการ
นำไปใช้สร้างโปรแกรมประเภทบรรณาธิการข้อความ(text editor) หรือโปรแกรมประเภทประมวลผลคำ (wordprocessing) ซึ่งมีการทำงานที่อำนวยความสะดวกหลายอย่างเช่น การตรวจสอบข้อความ การจัดแนวข้อความในแต่ละย่อหน้า และการค้นหาคำ เป็นต้น
การกำหนดค่าคงตัวสตริงสามารถกำหนดได้ทั้งนอกและในฟังก์ชัน เมื่อกำหนดไว้นอกฟังก์ชัน ชื่อค่าคงตัวจะเป็นพอยเตอร์ชี้ไปยังหน่วยความจำที่เก็บสตริงนั้น เมื่อกำหนดไว้ในฟังก์ชัน จะเป็นพอยเตอร์ไปยังหน่วยความจำที่เก็บตัวมันเอง
การกำหนดค่าให้กับสตริงนั้น เราจะใช้เครื่องหมาย doublequote (“ ”) เช่น “abc” คือ ชุดของอักขระที่มีขนาด 4 (รวม \0 ด้วย)
ข้อสังเกต
string constant are different from character constant
#define NME “Semi”
main ( ){
char *cpntr;cpntr=NME;
printf(“con\n”);printf(“%s, %u, %c\n”, “con”, “duc”,*“tor”);
printf(““%s, %u, %c\n”, NME, NME,*NME);
printf(““%s, %u, %c\n”, cpntr, cpntr,*cpntr);
}
ผลการรันโปรแกรม
con
con, 37, t
Semi, 16, S
Semi, 16, S
การกำหนดค่าคงตัวสตริงให้แก่ตัวแปรพอยต์เตอร์และอะเรย์สามารถกำหนดค่าคงตัวสตริงให้พอยเตอร์หรืออะเรย์ได้ในฐานะค่าเริ่มต้น
เช่น main ( ) {
char ary[ ] = “This is the house. ”;
char *cpntr=“This is the door.”;
printf(“%s %s”,ary,cpntr);
ผลการรันโปรแกรมจะเห็นได้ว่าการใช้งานดูไม่แตกต่างกัน
แต่ aryเป็นตัวแปรอะเรย์ ค่าที่ให้จะต้องเป็นค่าข้อมูลในอะเรย์ส่วน cpntr
เป็นพอยเตอร์ ค่าที่ให้นั้นไม่ใช่ค่าข้อมูล แต่เป็นค่าแอดเดรสเริ่มต้นของสตริง
(ค่าคงตัวสตริงเป็นทั้งข้อมูลสตริงและพอยเตอร์) นอกจากนี้ยังสามารถเพิ่มลดค่า
ตัวแปรพอยเตอร์ได้ แต่สำหรับอะเรย์ทำไม่ได้
การกำหนดตัวแปรสตริงในการกำหนดตัวแปรของสตริง
อาศัยหลักการของอะเรย์ เพราะ สตริงก็คืออะเรย์ของอักขระที่ปิดท้ายด้วย
null character (\0) และมีฟังก์ชันพิเศษสำหรับทำงานกับสตริงโดยเฉพาะ
เช่นต้องการสตริงสำหรับเก็บชื่อบุคคลยาวไม่เกิน 30อักขระ
ต้องกำหนดเป็นอะเรย์ขนาด 31 ช่อง เพื่อเก็บ null character อีก 1 ช่อง
main ( ) {char name[31];
printf(“Hi, What’s your name?\n”);
gets(name);
printf(“Nice to meet you, %s\n”);
}
ผลการรันโปรแกรม
Hi, What’s your name?
Jame Smith
Nice to meet you, Jame Smith
เป็นโครงสร้างข้อมูลที่ข้อมูลแต่ละตัวไม่มีความสัมพันธ์กัน
ในภาษาซีจะไม่มีประเภทข้อมูลแบบเซ็ตนี้เหมือนกับในภาษาปาสคาล
แต่สามารถใช้หลักการของการดำเนินงานแบบเช็ตมาใช้ได้
วิธีการแก้ปัญหาเบื้องต้น
- จะต้องกำหนดเซ็ตของผู้เรียนที่ลงทะเบียนเรียนในแต่ละวิชา
- นำเซ็ตดังกล่าวที่ได้มาทำการ intersection กัน หากมีเซ็ตใดที่
ทำการ intersect กันแล้ว มีข้อมูลสมาชิกในเซ็ตที่ซ้ำกันอยู่
จะไม่สามารถจัดให้วิชาดังกล่าวอยู่ในวันเวลาเดียวกันได้ตัวอย่างดังกล่าว
เป็นการนำแนวความคิดเรื่องการจัดการแบบเช็ตมาประยุกใช้งานโครงสร้างข้อมูลแบบสตริงสตริง (String) หรือ สตริงของอักขระ (CharacterString) เป็นข้อมูลที่ประกอบไปด้วย
ตัวอักษร ตัวเลขหรือเครื่องหมายเรียงติดต่อกันไป
รวมทั้งช่องว่างการประยุกต์ใช้คอมพิวเตอร์ที่เกี่ยวกับข้อมูลที่เป็นสตริงมีการ
นำไปใช้สร้างโปรแกรมประเภทบรรณาธิการข้อความ(text editor) หรือโปรแกรมประเภทประมวลผลคำ (wordprocessing) ซึ่งมีการทำงานที่อำนวยความสะดวกหลายอย่างเช่น การตรวจสอบข้อความ การจัดแนวข้อความในแต่ละย่อหน้า และการค้นหาคำ เป็นต้น
การกำหนดค่าคงตัวสตริงสามารถกำหนดได้ทั้งนอกและในฟังก์ชัน เมื่อกำหนดไว้นอกฟังก์ชัน ชื่อค่าคงตัวจะเป็นพอยเตอร์ชี้ไปยังหน่วยความจำที่เก็บสตริงนั้น เมื่อกำหนดไว้ในฟังก์ชัน จะเป็นพอยเตอร์ไปยังหน่วยความจำที่เก็บตัวมันเอง
การกำหนดค่าให้กับสตริงนั้น เราจะใช้เครื่องหมาย doublequote (“ ”) เช่น “abc” คือ ชุดของอักขระที่มีขนาด 4 (รวม \0 ด้วย)
ข้อสังเกต
string constant are different from character constant
#define NME “Semi”
main ( ){
char *cpntr;cpntr=NME;
printf(“con\n”);printf(“%s, %u, %c\n”, “con”, “duc”,*“tor”);
printf(““%s, %u, %c\n”, NME, NME,*NME);
printf(““%s, %u, %c\n”, cpntr, cpntr,*cpntr);
}
ผลการรันโปรแกรม
con
con, 37, t
Semi, 16, S
Semi, 16, S
การกำหนดค่าคงตัวสตริงให้แก่ตัวแปรพอยต์เตอร์และอะเรย์สามารถกำหนดค่าคงตัวสตริงให้พอยเตอร์หรืออะเรย์ได้ในฐานะค่าเริ่มต้น
เช่น main ( ) {
char ary[ ] = “This is the house. ”;
char *cpntr=“This is the door.”;
printf(“%s %s”,ary,cpntr);
ผลการรันโปรแกรมจะเห็นได้ว่าการใช้งานดูไม่แตกต่างกัน
แต่ aryเป็นตัวแปรอะเรย์ ค่าที่ให้จะต้องเป็นค่าข้อมูลในอะเรย์ส่วน cpntr
เป็นพอยเตอร์ ค่าที่ให้นั้นไม่ใช่ค่าข้อมูล แต่เป็นค่าแอดเดรสเริ่มต้นของสตริง
(ค่าคงตัวสตริงเป็นทั้งข้อมูลสตริงและพอยเตอร์) นอกจากนี้ยังสามารถเพิ่มลดค่า
ตัวแปรพอยเตอร์ได้ แต่สำหรับอะเรย์ทำไม่ได้
การกำหนดตัวแปรสตริงในการกำหนดตัวแปรของสตริง
อาศัยหลักการของอะเรย์ เพราะ สตริงก็คืออะเรย์ของอักขระที่ปิดท้ายด้วย
null character (\0) และมีฟังก์ชันพิเศษสำหรับทำงานกับสตริงโดยเฉพาะ
เช่นต้องการสตริงสำหรับเก็บชื่อบุคคลยาวไม่เกิน 30อักขระ
ต้องกำหนดเป็นอะเรย์ขนาด 31 ช่อง เพื่อเก็บ null character อีก 1 ช่อง
main ( ) {char name[31];
printf(“Hi, What’s your name?\n”);
gets(name);
printf(“Nice to meet you, %s\n”);
}
ผลการรันโปรแกรม
Hi, What’s your name?
Jame Smith
Nice to meet you, Jame Smith
วันอังคารที่ 30 มิถุนายน พ.ศ. 2552
DTS03 30/06/2552
อะเรย์เป็นโครงสร้างข้อมูลที่เรียกว่า Linear List มีลักษณะคล้ายเซ็ตในคณิตศาสตร์ คือ อะเรย์จะประกอบด้วยสมาชิกที่มีจำนวนคงที่ มีรูปแบบข้อมูลเป็นแบบเดียวกัน สมาชิกแต่ละตัวใช้เนื้อที่จัดเก็บที่มีขนาดเท่ากัน เรียงต่อเนื่องในหน่วยความจำหลัก
อาร์เรย์ 1 มิติเป็นตัวแปรที่เก็บข้อมูลเพียงแถวเดียวหรือชั้นเดียวเช่นในการคำนวณหาสมาชิกของอาร์เรย์ 1 มิติทำได้ดังนี้จำนวนสมาชิกของอาร์เรย์ = (u-l)+1u คือค่าสูงสุด หรือ Upper boundl คือค่าต่ำสุด หรือ Lower bound ส่วน 2 มิติสามารถหาได้ดังนี้จำนวนสมาชิก = M x N
รูปแบบของการประกาศตัวแปรอาร์เรย์มิติเดียวtype array-name[n];type คือ ชนิดของตัวแปรอาร์เรย์ที่จะสร้างขึ้น เช่น int,float,char เป็นต้นarray-name คือ ชื่อของตัวแปรอาร์เรย์ที่ต้องตั้งให้สื่อและเข้ากับชนิดของตัวแปรและจะต้องไม่ไปตรงกับคำสงวนของภาษาซีด้วยn คือขนาดของตัวแปรอาร์เรย์ที่จะสร้างขึ้น
อาร์เรย์ 2 มิติมีลักษณะการกำหนดตำแหน่งแบบแถวและคอลัมน์รูปแบบของการประกาศตัวแปรอาร์เรย์ 2 มิติtype array-name[n][m];type คือ ชนิดของตัวแปรอาร์เรย์ที่จะสร้างขึ้น เช่น int,float,char เป็นต้นarray-name คือ ชื่อของตัวแปรอาร์เรย์ที่ต้องตั้งให้สื่อและเข้ากับชนิดของตัวแปรและจะต้องไม่ไปตรงกับคำสงวนของภาษาซีด้วยn คือ จำนวนแถวของตัวแปรอาร์เรย์m คือ จำนวนคอลัมน์ของตัวแปรอาร์เรย์เช่น int num[3][5];
Structure โครงสร้างข้อมูลหมายถึง การที่นำข้อมูลที่มีความเกี่ยวข้องกัน เช่น ข้อมูลของนักศึกษาที่อาจประกอบด้วยชื่อ,นามสกุล,อายุ,เพศ,ชั้นเรียน มารวมกันและจัดทำเป็นโครงสร้างข้อมูล
struct คือ คำที่ใช้กำหนดโครงสร้างข้อมูล(ต้องมีเสมอ)name คือ ชื่อของโครงสร้างข้อมูลที่จะสร้างขึ้นtype var-1,type var-2 คือชื่อตัวแปรในกลุ่มโครงสร้างข้อมูลstruct-variable คือชื่อของตัวแปรชนิดโครงสร้างที่ต้องการสร้างขึ้นจะมีลักษณะโครงสร้างภายในเหมือนกับโครงสร้างข้อมูลที่กำหนด
ตัวอย่าง struct student student1;
การอ้างถึงสมาชิกในตัวแปรชนิดโครงสร้างstruct-name.variable-namestruct-name คือ ชื่อของตัวแปรชนิดโครงสร้าง (ไม่ใช่ชื่อโครงสร้าง). คือเครื่องหมายขั้นระหว่างชื่อตัวแปรชนิดโครงสร้างกับตัวแปรที่เป็นสมาชิก
variable-name คือชื่อของตัวแปรที่เป็นสมาชิกการกำหนดข้อมูลให้ตัวแปรชนิดโครงสร้างเราสามารถกำหนดได้เหมือนตัวแปรทั่วไปแต่ต้องอ้างอิงถึงสมาชิกให้ถูกต้อง เช่น student1.age = 15;student1.sex = 'M'; กรณีถ้าเป็นอาร์เรย์ของตัวแปรชนิดโครงสร้างสามารถเขียนได้ดังนี้ student1[0].age = 15;
อาร์เรย์ 1 มิติเป็นตัวแปรที่เก็บข้อมูลเพียงแถวเดียวหรือชั้นเดียวเช่นในการคำนวณหาสมาชิกของอาร์เรย์ 1 มิติทำได้ดังนี้จำนวนสมาชิกของอาร์เรย์ = (u-l)+1u คือค่าสูงสุด หรือ Upper boundl คือค่าต่ำสุด หรือ Lower bound ส่วน 2 มิติสามารถหาได้ดังนี้จำนวนสมาชิก = M x N
รูปแบบของการประกาศตัวแปรอาร์เรย์มิติเดียวtype array-name[n];type คือ ชนิดของตัวแปรอาร์เรย์ที่จะสร้างขึ้น เช่น int,float,char เป็นต้นarray-name คือ ชื่อของตัวแปรอาร์เรย์ที่ต้องตั้งให้สื่อและเข้ากับชนิดของตัวแปรและจะต้องไม่ไปตรงกับคำสงวนของภาษาซีด้วยn คือขนาดของตัวแปรอาร์เรย์ที่จะสร้างขึ้น
อาร์เรย์ 2 มิติมีลักษณะการกำหนดตำแหน่งแบบแถวและคอลัมน์รูปแบบของการประกาศตัวแปรอาร์เรย์ 2 มิติtype array-name[n][m];type คือ ชนิดของตัวแปรอาร์เรย์ที่จะสร้างขึ้น เช่น int,float,char เป็นต้นarray-name คือ ชื่อของตัวแปรอาร์เรย์ที่ต้องตั้งให้สื่อและเข้ากับชนิดของตัวแปรและจะต้องไม่ไปตรงกับคำสงวนของภาษาซีด้วยn คือ จำนวนแถวของตัวแปรอาร์เรย์m คือ จำนวนคอลัมน์ของตัวแปรอาร์เรย์เช่น int num[3][5];
Structure โครงสร้างข้อมูลหมายถึง การที่นำข้อมูลที่มีความเกี่ยวข้องกัน เช่น ข้อมูลของนักศึกษาที่อาจประกอบด้วยชื่อ,นามสกุล,อายุ,เพศ,ชั้นเรียน มารวมกันและจัดทำเป็นโครงสร้างข้อมูล
struct คือ คำที่ใช้กำหนดโครงสร้างข้อมูล(ต้องมีเสมอ)name คือ ชื่อของโครงสร้างข้อมูลที่จะสร้างขึ้นtype var-1,type var-2 คือชื่อตัวแปรในกลุ่มโครงสร้างข้อมูลstruct-variable คือชื่อของตัวแปรชนิดโครงสร้างที่ต้องการสร้างขึ้นจะมีลักษณะโครงสร้างภายในเหมือนกับโครงสร้างข้อมูลที่กำหนด
ตัวอย่าง struct student student1;
การอ้างถึงสมาชิกในตัวแปรชนิดโครงสร้างstruct-name.variable-namestruct-name คือ ชื่อของตัวแปรชนิดโครงสร้าง (ไม่ใช่ชื่อโครงสร้าง). คือเครื่องหมายขั้นระหว่างชื่อตัวแปรชนิดโครงสร้างกับตัวแปรที่เป็นสมาชิก
variable-name คือชื่อของตัวแปรที่เป็นสมาชิกการกำหนดข้อมูลให้ตัวแปรชนิดโครงสร้างเราสามารถกำหนดได้เหมือนตัวแปรทั่วไปแต่ต้องอ้างอิงถึงสมาชิกให้ถูกต้อง เช่น student1.age = 15;student1.sex = 'M'; กรณีถ้าเป็นอาร์เรย์ของตัวแปรชนิดโครงสร้างสามารถเขียนได้ดังนี้ student1[0].age = 15;
หน่วยวัดความจำข้อมูล
1 กิโลไบต์ = 1,024 ไบต์
1 เมกะไบต์ = 1,048,576 ไบต์ หรือ 1,024 กิโลไบต์
1 จิกะไบต์ = 1,073,741,824 ไบต์ หรือ 1,024 เมกะไบต์
1 เทระไบต์ = 1,099,511,627,776 ไบต์ หรือ 1,024 จิกะไบต์
เพตะไบต์ PB 1015 ≈ เพบิไบต์ PiB 250
เอกซะไบต์ EB 1018 ≈ เอกซ์บิไบต์ EiB 260
เซตตะไบต์ ZB 1021
ยอตตะไบต์ YB 1024
DTS01 16/06/2552
ปฐมนิเทศ
โครงสร้างข้อมูล (DATA STRUCTURE)
ผู้สอน : อาจารย์ปรมัตถ์ปัญปรัชญ์ ต้องประสงค์
E-mail : phorramatpanyaprat@hotmail.com
การเก็บคะแนน 100 แบ่งออกเป็น
60:40
*ความสำคัญของวิชาโครงสร้างข้อมูล
*โครงสร้างข้อมูล หมายถึง ความสัมพันธ์ระหว่างข้อมูลที่อยู่ในโครงสร้างนั้น ๆ เช่น การสร้างบ้าน ก็ต้องมีส่วนประกอบในการสร้าง ได้แก่ หิน ทราย ปูน เป็นต้น
สอนการสร้าง blogger ก่อนที่จะสร้าง Blog ต้องมี E-mail ของ gmail ก่อน โดยการตั้ง ชื่อ E-mail คือ u ตามด้วยรหัสประจำตัว
เช่น u50132792087@gmail.com
โครงสร้างข้อมูล (DATA STRUCTURE)
ผู้สอน : อาจารย์ปรมัตถ์ปัญปรัชญ์ ต้องประสงค์
E-mail : phorramatpanyaprat@hotmail.com
การเก็บคะแนน 100 แบ่งออกเป็น
60:40
*ความสำคัญของวิชาโครงสร้างข้อมูล
*โครงสร้างข้อมูล หมายถึง ความสัมพันธ์ระหว่างข้อมูลที่อยู่ในโครงสร้างนั้น ๆ เช่น การสร้างบ้าน ก็ต้องมีส่วนประกอบในการสร้าง ได้แก่ หิน ทราย ปูน เป็นต้น
สอนการสร้าง blogger ก่อนที่จะสร้าง Blog ต้องมี E-mail ของ gmail ก่อน โดยการตั้ง ชื่อ E-mail คือ u ตามด้วยรหัสประจำตัว
เช่น u50132792087@gmail.com
วันจันทร์ที่ 29 มิถุนายน พ.ศ. 2552
ประวัติ
 นายชัยพล เลี้ยงใจ ชื่อเล่น เชน
นายชัยพล เลี้ยงใจ ชื่อเล่น เชน รหัสประจำตัว 50132792087
Mr.Chaiyapol Liangjai
หลักสูตร การบริหารธุรกิจ (แขนงคอมพิวเตอร์ธุรกิจ)
คณะวิทยาการจัดการ มหาวิทยาลัยราชภัฏสวนดุสิต
E-mail : u50132792087@gmail.com
Tel. 081-491-1683
วันศุกร์ที่ 26 มิถุนายน พ.ศ. 2552
DTS02 23/06/2552
โครงสร้างข้อมูล เกิดจากคำสองคำได้แก่ “โครงสร้าง” และ “ข้อมูล” ซึ่งคำว่า “โครงสร้าง” เป็นความสัมพันธ์ระหว่างสมาชิกในกลุ่ม ดังนั้นโครงสร้างข้อมูลจึงหมายถึงความสัมพันธ์ระหว่างข้อมูลที่อยู่ในโครงสร้างนั้นๆ
ประเภทของโครงสร้างข้อมูล
ในภาษาคอมพิวเตอร์จะแบ่งเป็น 2 ประเภท คือ
1. โครงสร้างข้อมูลทางกายภาพ
- เป็นโครงสร้างข้อมูลที่ใช้โดยทั่วไปในภาษาคอมพิวเตอร์แบ่งออกเป็น 2 ประเภทตามลักษณะข้อมูล
1.1 ข้อมูลเบื้องต้น Primitive Data Types
ได้แก่ จำนวนเต็ม จำนวนจริง และตัวอักขระ
1.2 ข้อมูลโครงสร้าง Structured Data Types
ได้แก่ แถวลำดับ ระเบียนข้อมูล และแฟ้มข้อมูล
2. โครงสร้างข้อมูลทางตรรกะ
-เป็นโครงสร้างข้อมูลที่เกิดจากจินตนาการของผู้ใช้เพื่อใช้ในการแก้ปัญหาในโปรแกรมที่สร้างขึ้น แบ่ง เป็น 2 ประเภท
2.1 โครงสร้างข้อมูลเชิงเส้น Linear Data Structures
ความสัมพันธ์ของข้อมูลจะเรียงต่อเนื่องกัน เช่น ลิสต์ สแตก คิว สตริง
2.2 โครงสร้างข้อมูลทางตรรกะ Non-Linear Data Structures
ข้อมูลแต่ละตัวสามารถมีความสัมพันธ์กับข้อมูลอื่นได้หลายตัว
ได้แก่ ทรี และกราฟ
ขั้นตอนวิธีที่ดีควรมีคุณสมบัติ ดังนี้
1. มีความถูกต้อง
2. ใช้เวลาในการปฏิบัติงานน้อยที่สุด
3. สั้น กระชับ มีเฉพาะขั้นตอนที่จำเป็นเท่านั้น
4. ใช้หน่วยความจำน้อยที่สุด
5. มีความยืดหนุ่นในการใช้งาน
6. ใช้เวลาในการพัฒนาน้อยที่สุด
7. ง่ายต่อการทำความเข้าใจ
ภาษาขั้นตอนวิธี Algorithm Language
เป็ภาษาสำหรับเขียนขั้นตอนวิธี มีรูปแบบที่สั้น กระชับและรัดกุมและมีข้อกำหนด ดังต่อไปนี้
(การรับค่านั่นเอง)
1. ตัแปรจะต้องเขียนแทนด้วยตัวอักษรหรือตัวอักษรผสมตัวเลข
2. การกำหนดค่าให้ตัวแปร ใช้เครื่องหมาย
3. นิพจน์ที่เป็นการคำนวณจะมีลำดับขั้นของการคำนวณตามลำดับ
นิพจน์ที่เป็นตรรกศาสตร์ จะใช้เครื่องหมายใน
การเปรียบเทียบ คือ
= เท่ากับ = ไม่เท่ากับ
< น้อยกว่า > มากกว่า
≤ น้อยกว่าหรือเท่ากับ ≥ มากกว่าหรือเท่ากับ
4. ข้อความไปยังขั้นตอน ใช้รูปแบบ คือ
goto เลขที่ขั้นตอน
5. การเลือกทำตามเงื่อนไข จะต้องตรวจสอบเงื่อนไข
ก่อนทำงาน มีรูปแบบดังนี้
- แบบทางเลือกเดียว ใช้รูปแบบ คือ
if (condition) then statement 1
- แบบสองทางเลือก ใช้รูปแบบ คือ
if (condition) then statement 1
else statement
6. การทำงานแบบซ้ำ
- แบบทดสอบเงื่อนไขที่ต้นวงรอบ มีรูปแบบ ดังนี้
while (condition) do
statement
- แบบทำซ้ำด้วยจำนวนครั้งของการทำซ้ำคงที่ มีรูปแบบ
for a=b to n by c do
statement
7. คำอธิบาย เป็นข้อความที่อธิบายรายละเอียดของ
ขั้นตอนการทำงาน จะอยู่ในเครื่องหมาย / และ /
ภาษาธรรมชาติ
คำว่า ภาษาธรรมชาติ (อังกฤษ: natural language) นั้น ใช้เพื่อแยกความแตกต่างระหว่างภาษาทั่ว ๆ ไปที่เกิดขึ้นตามธรรมชาติเพื่อการสื่อสาร เช่น ภาษามนุษย์ ออกจากภาษาที่ถูกสร้างขึ้นอย่าง เช่น ภาษาโปรแกรมสำหรับสั่งงานคอมพิวเตอร์ หรือภาษาที่ใช้ในการศึกษาตรรกกะ
ประเภทของโครงสร้างข้อมูล
ในภาษาคอมพิวเตอร์จะแบ่งเป็น 2 ประเภท คือ
1. โครงสร้างข้อมูลทางกายภาพ
- เป็นโครงสร้างข้อมูลที่ใช้โดยทั่วไปในภาษาคอมพิวเตอร์แบ่งออกเป็น 2 ประเภทตามลักษณะข้อมูล
1.1 ข้อมูลเบื้องต้น Primitive Data Types
ได้แก่ จำนวนเต็ม จำนวนจริง และตัวอักขระ
1.2 ข้อมูลโครงสร้าง Structured Data Types
ได้แก่ แถวลำดับ ระเบียนข้อมูล และแฟ้มข้อมูล
2. โครงสร้างข้อมูลทางตรรกะ
-เป็นโครงสร้างข้อมูลที่เกิดจากจินตนาการของผู้ใช้เพื่อใช้ในการแก้ปัญหาในโปรแกรมที่สร้างขึ้น แบ่ง เป็น 2 ประเภท
2.1 โครงสร้างข้อมูลเชิงเส้น Linear Data Structures
ความสัมพันธ์ของข้อมูลจะเรียงต่อเนื่องกัน เช่น ลิสต์ สแตก คิว สตริง
2.2 โครงสร้างข้อมูลทางตรรกะ Non-Linear Data Structures
ข้อมูลแต่ละตัวสามารถมีความสัมพันธ์กับข้อมูลอื่นได้หลายตัว
ได้แก่ ทรี และกราฟ
ขั้นตอนวิธีที่ดีควรมีคุณสมบัติ ดังนี้
1. มีความถูกต้อง
2. ใช้เวลาในการปฏิบัติงานน้อยที่สุด
3. สั้น กระชับ มีเฉพาะขั้นตอนที่จำเป็นเท่านั้น
4. ใช้หน่วยความจำน้อยที่สุด
5. มีความยืดหนุ่นในการใช้งาน
6. ใช้เวลาในการพัฒนาน้อยที่สุด
7. ง่ายต่อการทำความเข้าใจ
ภาษาขั้นตอนวิธี Algorithm Language
เป็ภาษาสำหรับเขียนขั้นตอนวิธี มีรูปแบบที่สั้น กระชับและรัดกุมและมีข้อกำหนด ดังต่อไปนี้
(การรับค่านั่นเอง)
1. ตัแปรจะต้องเขียนแทนด้วยตัวอักษรหรือตัวอักษรผสมตัวเลข
2. การกำหนดค่าให้ตัวแปร ใช้เครื่องหมาย
3. นิพจน์ที่เป็นการคำนวณจะมีลำดับขั้นของการคำนวณตามลำดับ
นิพจน์ที่เป็นตรรกศาสตร์ จะใช้เครื่องหมายใน
การเปรียบเทียบ คือ
= เท่ากับ = ไม่เท่ากับ
< น้อยกว่า > มากกว่า
≤ น้อยกว่าหรือเท่ากับ ≥ มากกว่าหรือเท่ากับ
4. ข้อความไปยังขั้นตอน ใช้รูปแบบ คือ
goto เลขที่ขั้นตอน
5. การเลือกทำตามเงื่อนไข จะต้องตรวจสอบเงื่อนไข
ก่อนทำงาน มีรูปแบบดังนี้
- แบบทางเลือกเดียว ใช้รูปแบบ คือ
if (condition) then statement 1
- แบบสองทางเลือก ใช้รูปแบบ คือ
if (condition) then statement 1
else statement
6. การทำงานแบบซ้ำ
- แบบทดสอบเงื่อนไขที่ต้นวงรอบ มีรูปแบบ ดังนี้
while (condition) do
statement
- แบบทำซ้ำด้วยจำนวนครั้งของการทำซ้ำคงที่ มีรูปแบบ
for a=b to n by c do
statement
7. คำอธิบาย เป็นข้อความที่อธิบายรายละเอียดของ
ขั้นตอนการทำงาน จะอยู่ในเครื่องหมาย / และ /
ภาษาธรรมชาติ
คำว่า ภาษาธรรมชาติ (อังกฤษ: natural language) นั้น ใช้เพื่อแยกความแตกต่างระหว่างภาษาทั่ว ๆ ไปที่เกิดขึ้นตามธรรมชาติเพื่อการสื่อสาร เช่น ภาษามนุษย์ ออกจากภาษาที่ถูกสร้างขึ้นอย่าง เช่น ภาษาโปรแกรมสำหรับสั่งงานคอมพิวเตอร์ หรือภาษาที่ใช้ในการศึกษาตรรกกะ
Record - 23/6/2552
#include<stdio.h>
#include<string.h>
void main()
{
struct aircondition
{
char customer[15];
char brand [30];
char colour [20];
char personal[20];
int item;
unsigned int personal_id;
int number_air;
float price;
}air;
strcpy(air.customer,"Peiy");
strcpy(air.brand,"Mitsubishi");
strcpy(air.colour,"white");
strcpy(air.personal,"Chain");
air.item=1;
air.personal_id=12345;
air.number_air=69;
air.price=17350.50;
printf("Customer:%s\n",air.customer);
printf("Brand:%s\n",air.brand);
printf("Colour:%s\n",air.colour);
printf("Personal:%s\n",air.personal);
printf("Item:%d\n",air.item);
printf("Personal_id:%d\n",air.personal_id);
printf("Number_Air:%d\n",air.number_air);
printf("Price:%.2f\n",air.price);
}
#include<string.h>
void main()
{
struct aircondition
{
char customer[15];
char brand [30];
char colour [20];
char personal[20];
int item;
unsigned int personal_id;
int number_air;
float price;
}air;
strcpy(air.customer,"Peiy");
strcpy(air.brand,"Mitsubishi");
strcpy(air.colour,"white");
strcpy(air.personal,"Chain");
air.item=1;
air.personal_id=12345;
air.number_air=69;
air.price=17350.50;
printf("Customer:%s\n",air.customer);
printf("Brand:%s\n",air.brand);
printf("Colour:%s\n",air.colour);
printf("Personal:%s\n",air.personal);
printf("Item:%d\n",air.item);
printf("Personal_id:%d\n",air.personal_id);
printf("Number_Air:%d\n",air.number_air);
printf("Price:%.2f\n",air.price);
}
วันอังคารที่ 23 มิถุนายน พ.ศ. 2552
สมัครสมาชิก:
บทความ (Atom)